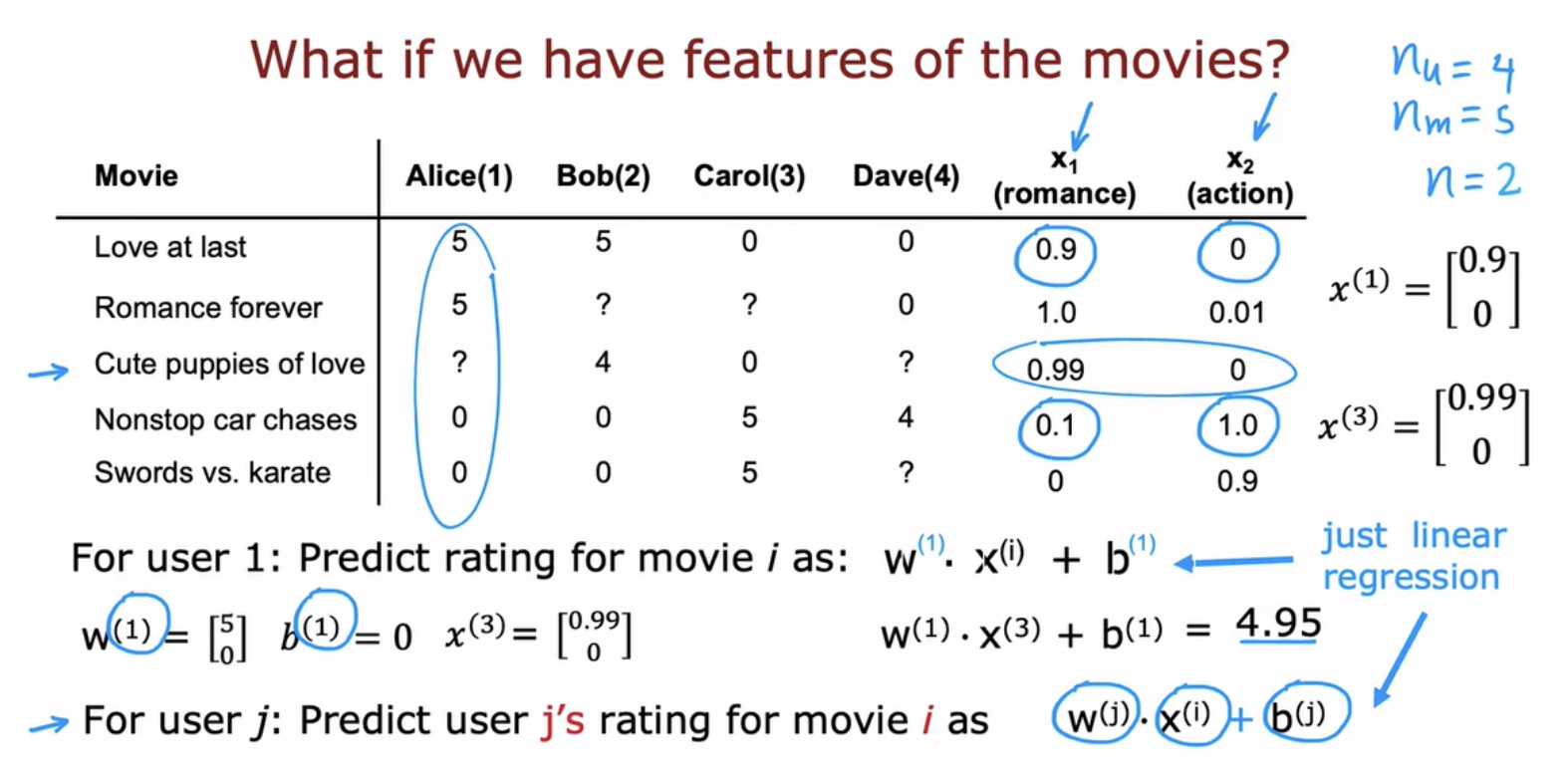
The user can rate the move from 0 to 5 stars. if you have features for each movie, the algorithm tells how much is this a romance movie and how much is this an action movie. Then you can use basically linear regression to learn to predict movie ratings.

But what if you don't have those features?
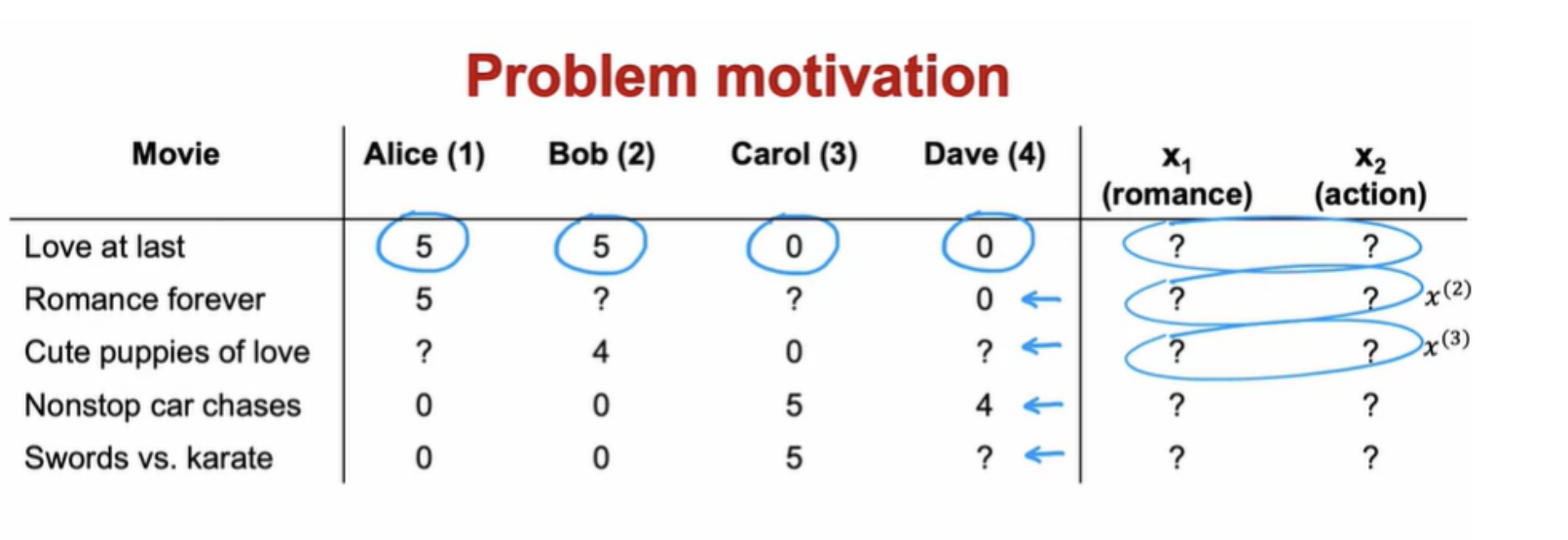
We can try to guess what might be reasonable features for movies. Alice rated movie one, 5, we should have that w (1).x(1) should be about equal to 5 and w (2).x(2) should also be about equal to 5 because Bob rated it 5. w (3).x(1) should be close to 0 andw (4).x(1) should be close to 0 as well. The question is, given these values for w that we have up here, what choice for x(1) will cause these values to be right?
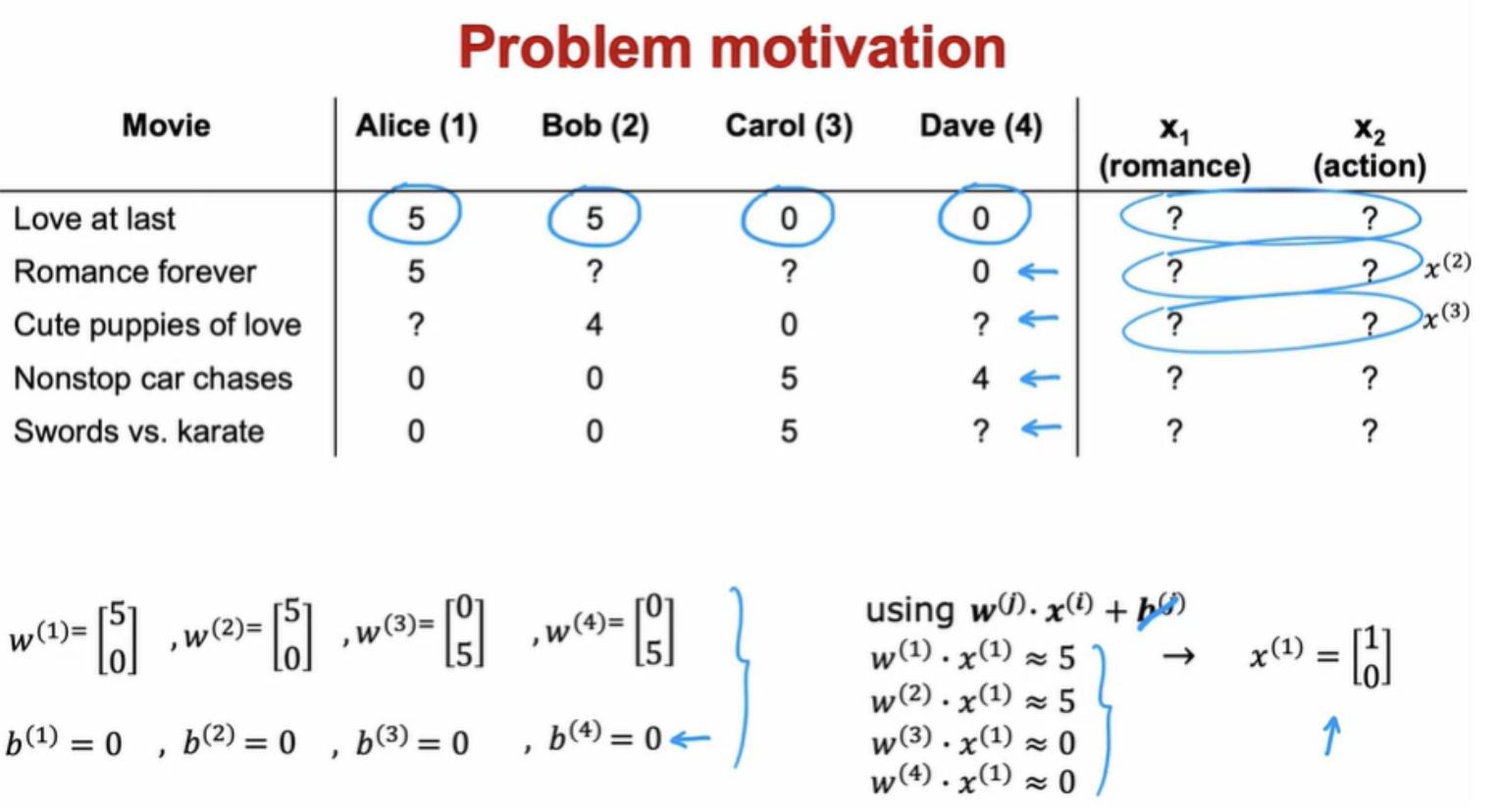
In collaborative filtering, you have ratings from multiple users of the same item with the same movie. That's what makes it possible to guess what are possible values for these features
For most machine learning applications the features had to be externally given. But in this algorithm, we can actually learn the features for a given movie
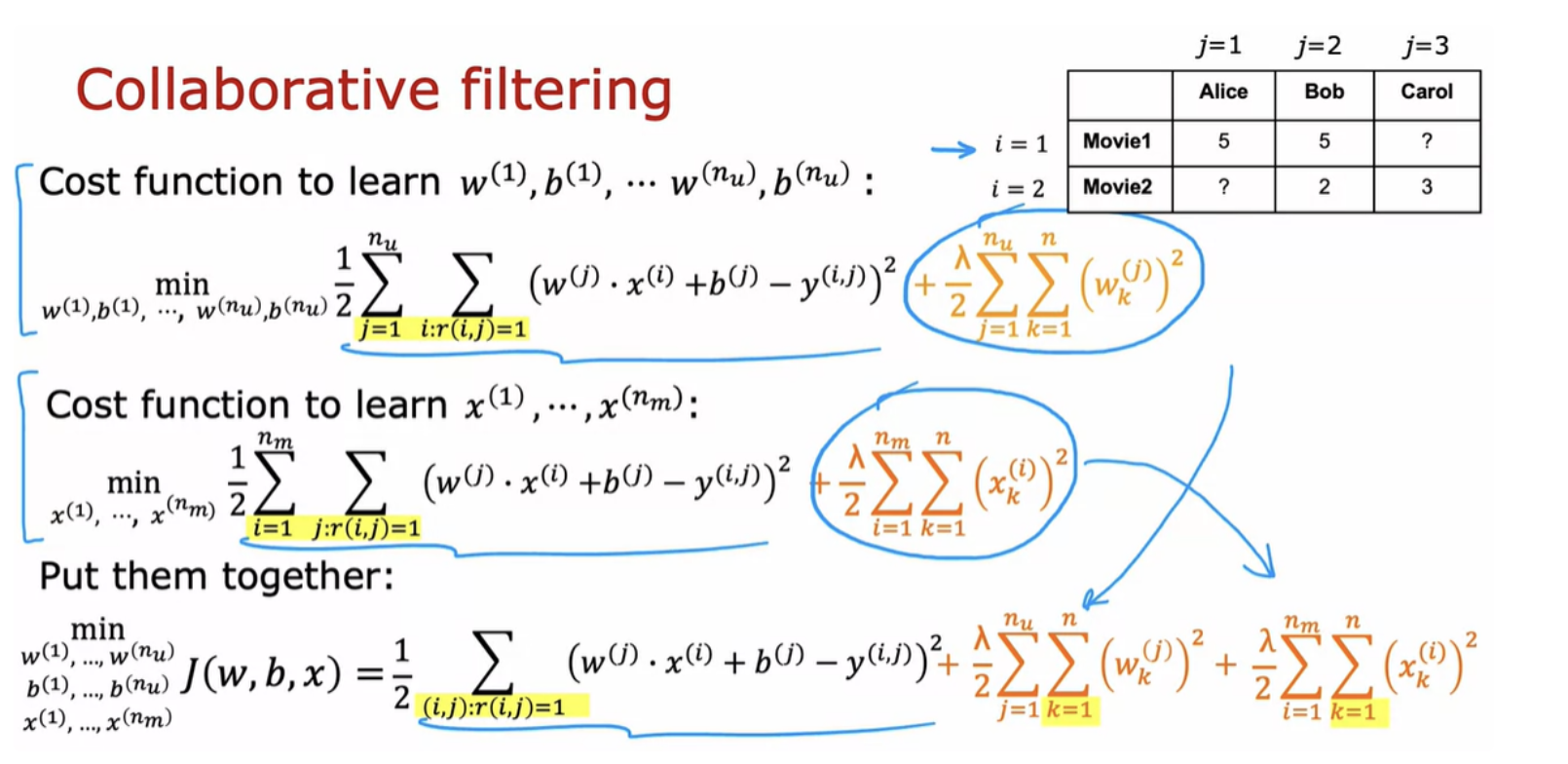
The name collaborative filtering refers that multiple users have rated the same movie collaboratively given you a sense of what this movie maybe like. This allows you to guess what are appropriate features for that movie. This in turn allows you to predict how other users that haven't yet rated that same movie may decide to rate it in the future. A very common use case of recommender systems is when you have binary labels such as that the user favors, or like, or interact with an item.
Many important applications of recommender systems or collective filtering algorithms involved binary labels, where instead of a user giving you a one to five star or zero to five star rating, they just give you a sense of they like this item or not. The process we'll use to generalize the algorithm will be very much reminiscent to how we have gone from linear regression to logistic regression, to predicting numbers to predicting a binary label.
You normalize the movie ratings to have a consistent average value. Add a fifth user Eve who has not yet rated any movies:

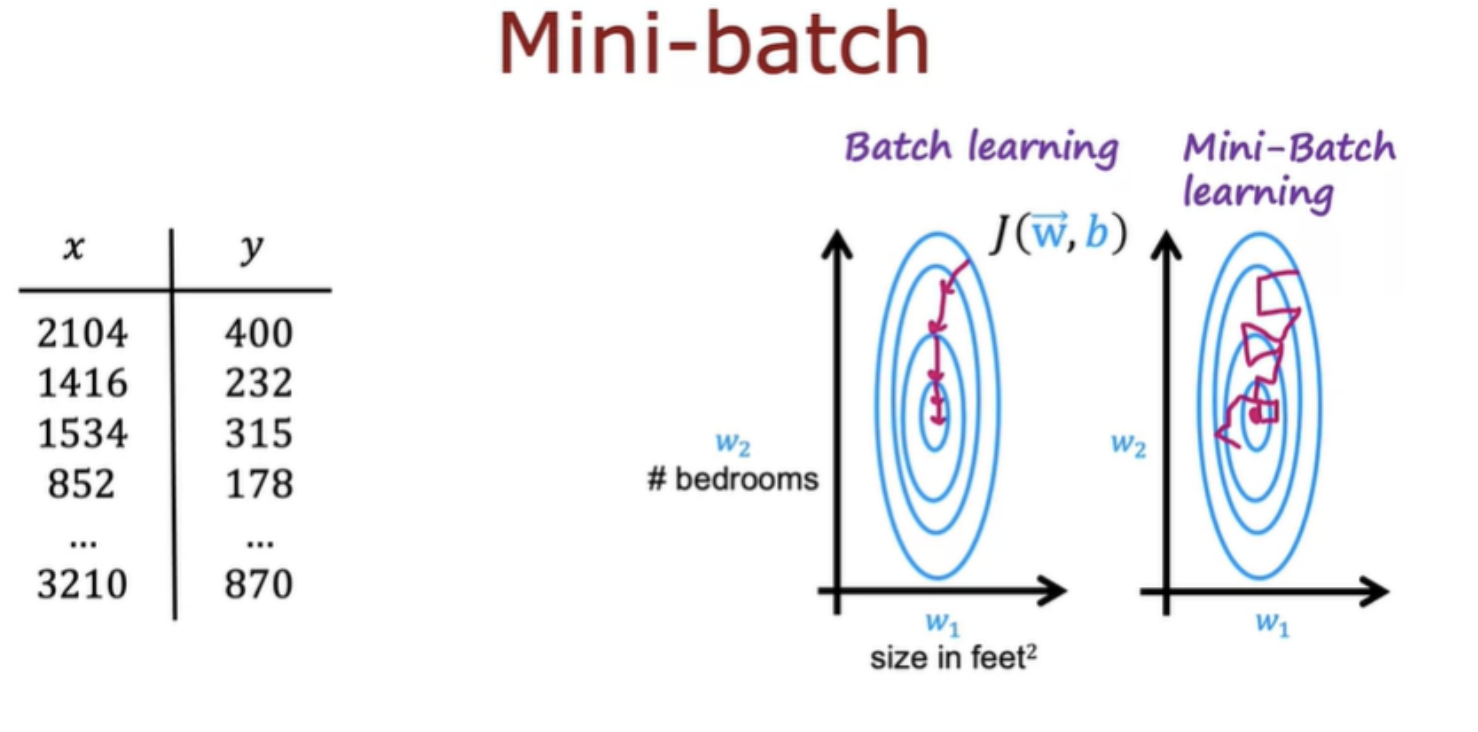
To carry out mean normalization we take all of these ratings and for each movie, compute the average rating that was given. We can use TensorFlow to implement the collaborative filtering algorithm. It's a great tool for building neural networks. Nut TensorFlow can also be very helpful for building other types of learning algorithms as well, like the collaborative filtering algorithm.
For many applications in order to implement gradient descent, you need to find the derivatives of the cost function, but TensorFlow can automatically figure out for you what are the derivatives of the cost function. All you have to do is implement the cost function and without needing to know any calculus, without needing to take derivatives yourself, you can get TensorFlow with just a few lines of code to compute that derivative term, that can be used to optimize the cost function.

This is a very powerful feature of TensorFlow called Auto Diff. And some other machine learning packages like pytorch also support Auto Diff (Auto Grad) for automatically taking derivatives. once you can compute derivatives automatically, you're not limited to just gradient descent. You can also use a more powerful optimization algorithm, like the adam optimization algorithm.
Book : AI and Machinelearning for coders : A programmers guide to Artificial Intelligence (Laurence Moroney)
Limitations of Collaborative filtering
Collaborative filtering - Recommend items to you based on ratings of users who gave similar ratings as you.
Content based filtering - Recommend items to you based on features of user and item to find good match


To summarize, in collaborative filtering, we had number of users give ratings of different items. In contrast, in content-based filtering, we have features of users and features of items, and we want to find a way to find good matches between the users and the items
A good way to develop a content-based filtering algorithm is to use deep learning.
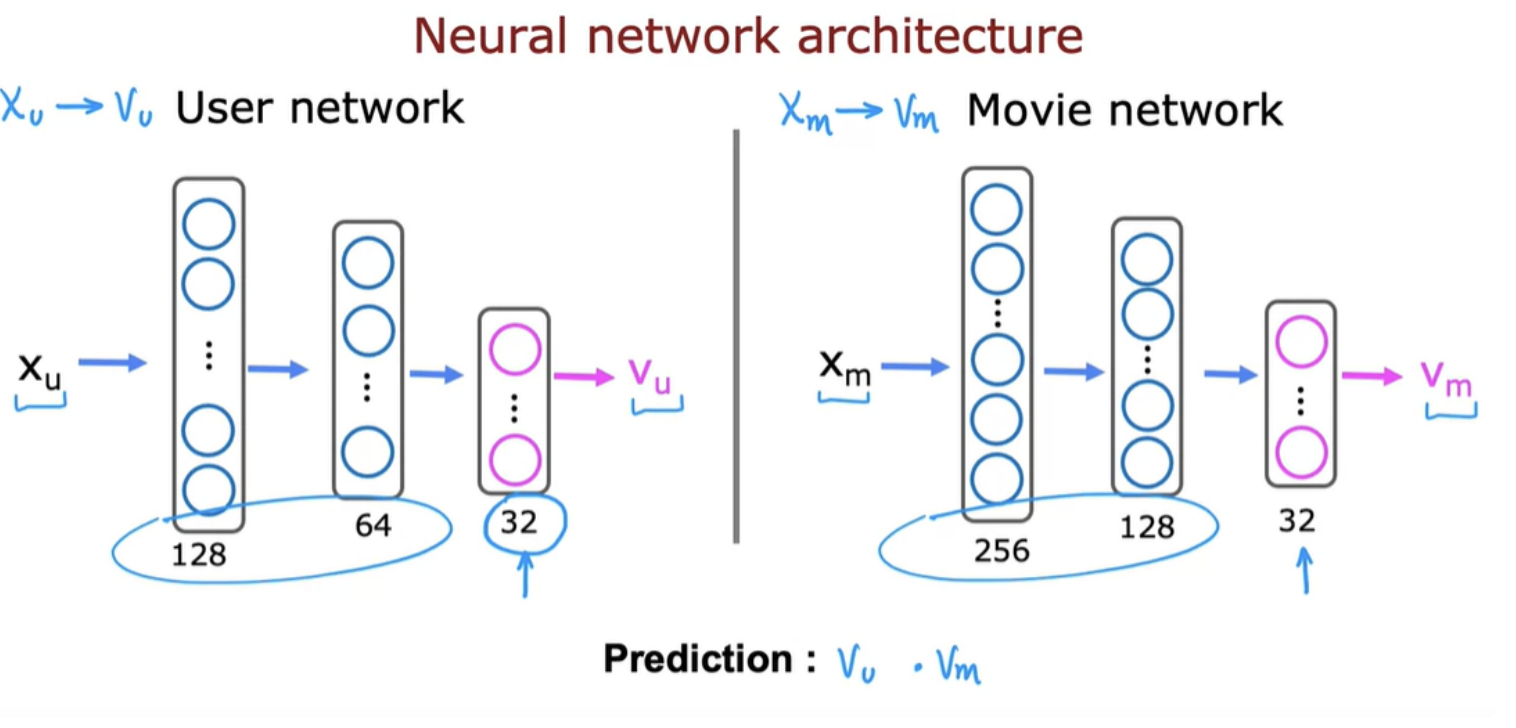
We need to train all the parameters of both the user network and the movie network.
PCA, or principal components analysis is an algorithm that lets you take data with a lot of features (for example 50, 1000, or more) and reduce the number of features to two or three features, so that you can plot it and visualize it.
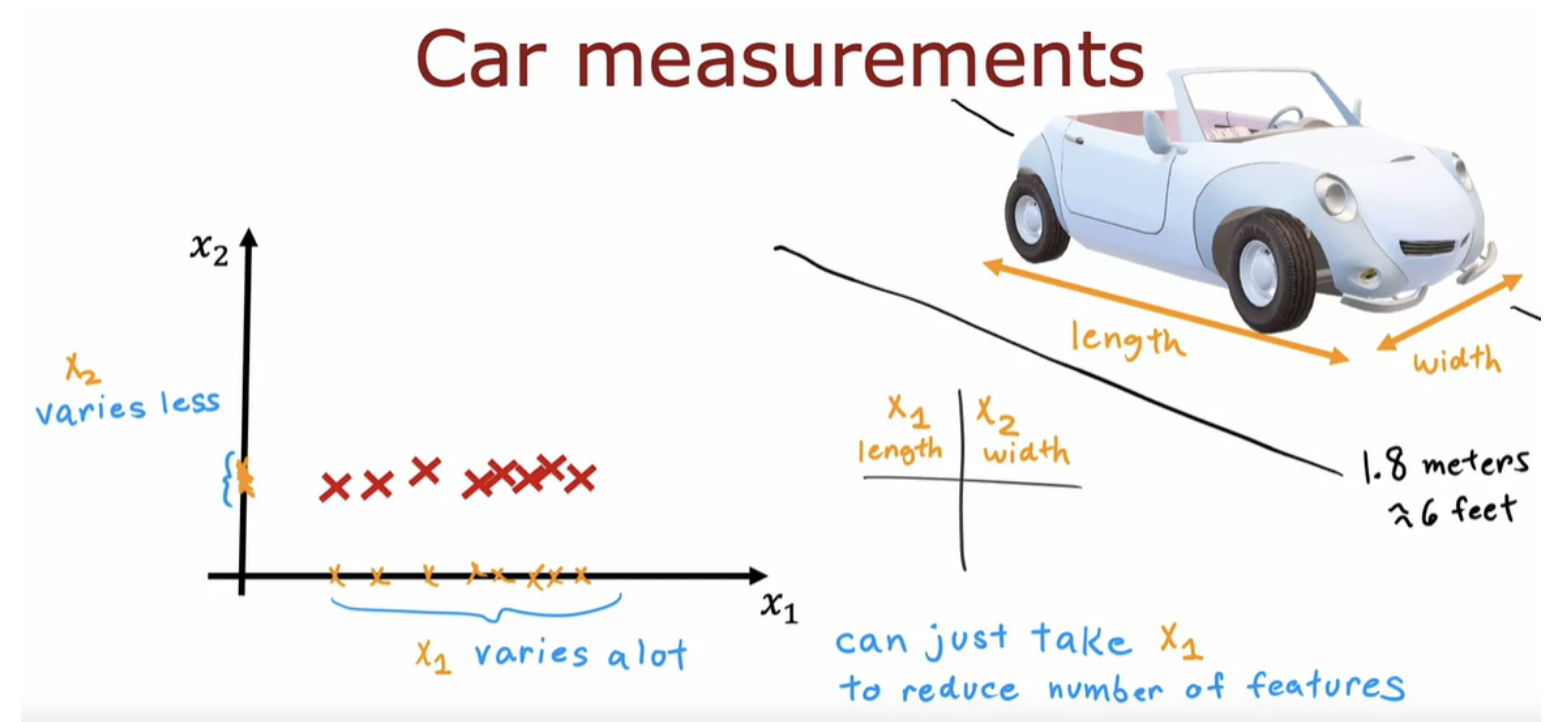
In the example only one of the two features seems to have a meaningful degree of variation
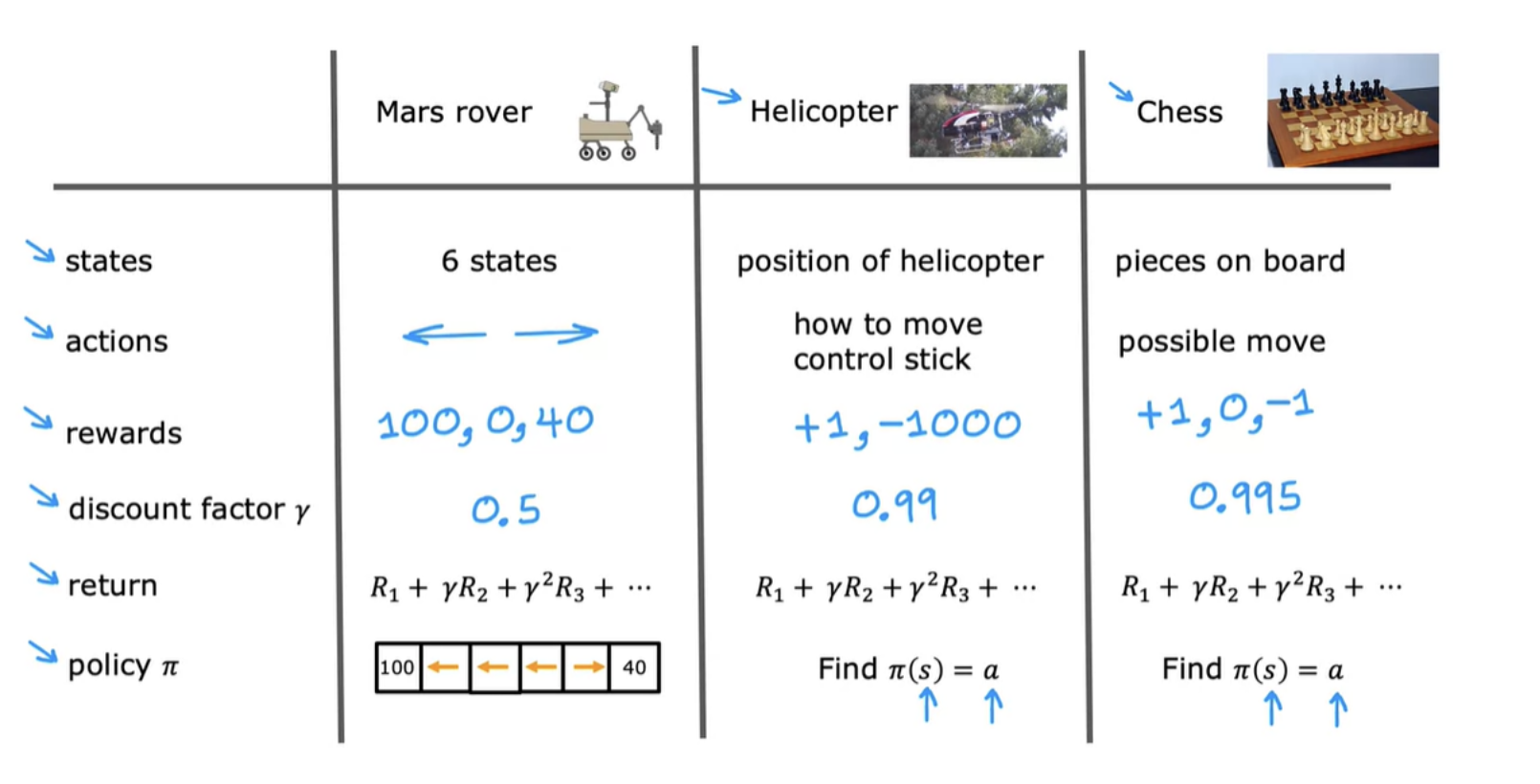
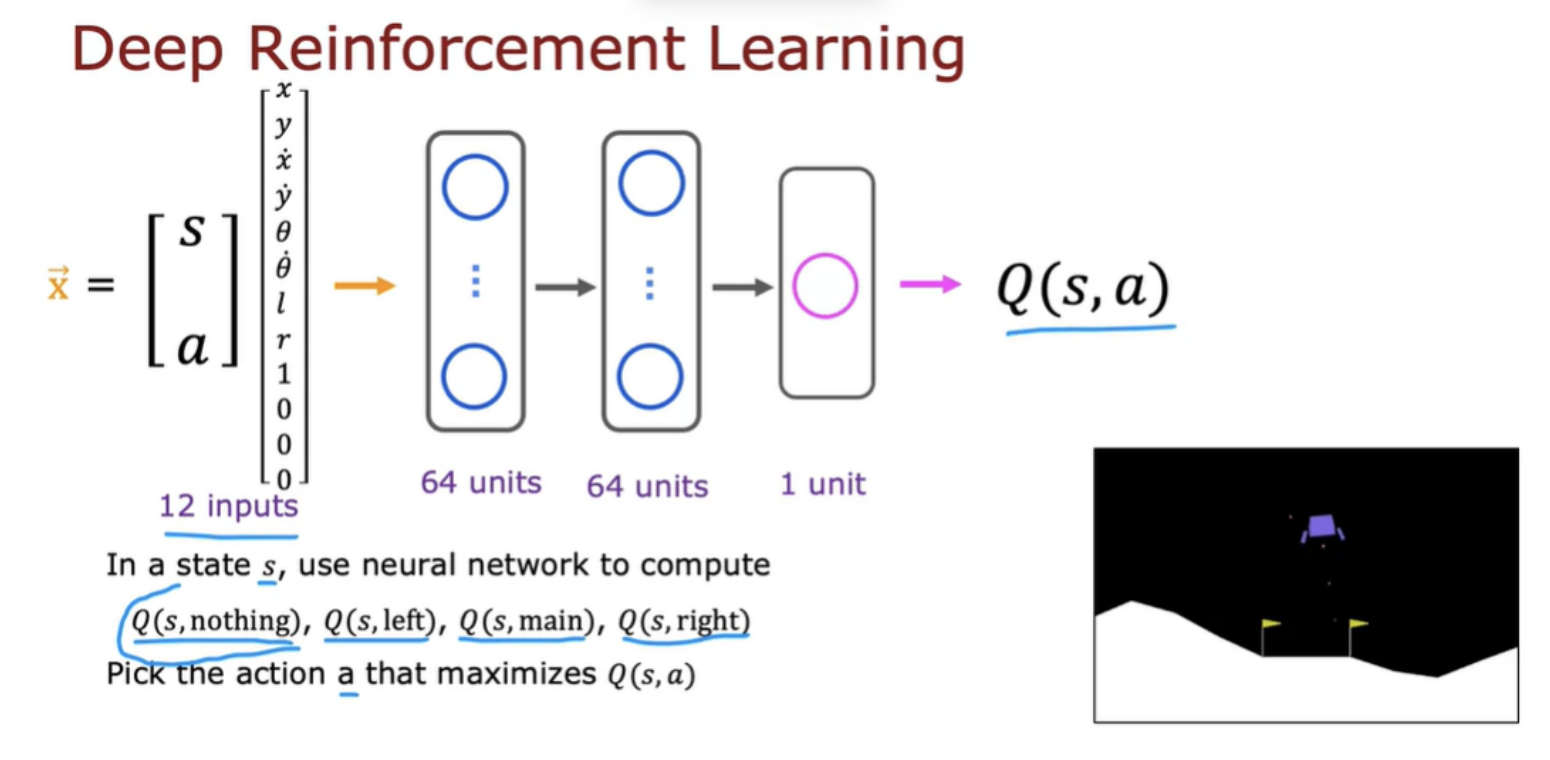
Programming a helicopter - In reinforcement learning, we get the position, orientation, speed of the helicopter (the state s). Our task is to find a function that maps from the state of the helicopter to an action a, meaning how far to push the two control sticks in order to keep the helicopter balanced in the air and flying and without crashing
One way you could attempt this problem is to use supervised learning. It turns out this is not a great approach for autonomous helicopter flying. The supervised learning approach doesn't work well and we instead use reinforcement learning. The key input to a reinforcement learning is something called the reward or the reward function which tells the helicopter when it's doing well and when it's doing poorly.
How do you know if a particular set of rewards is better or worse than a different set of rewards? The return in reinforcement learning allows us to capture that.