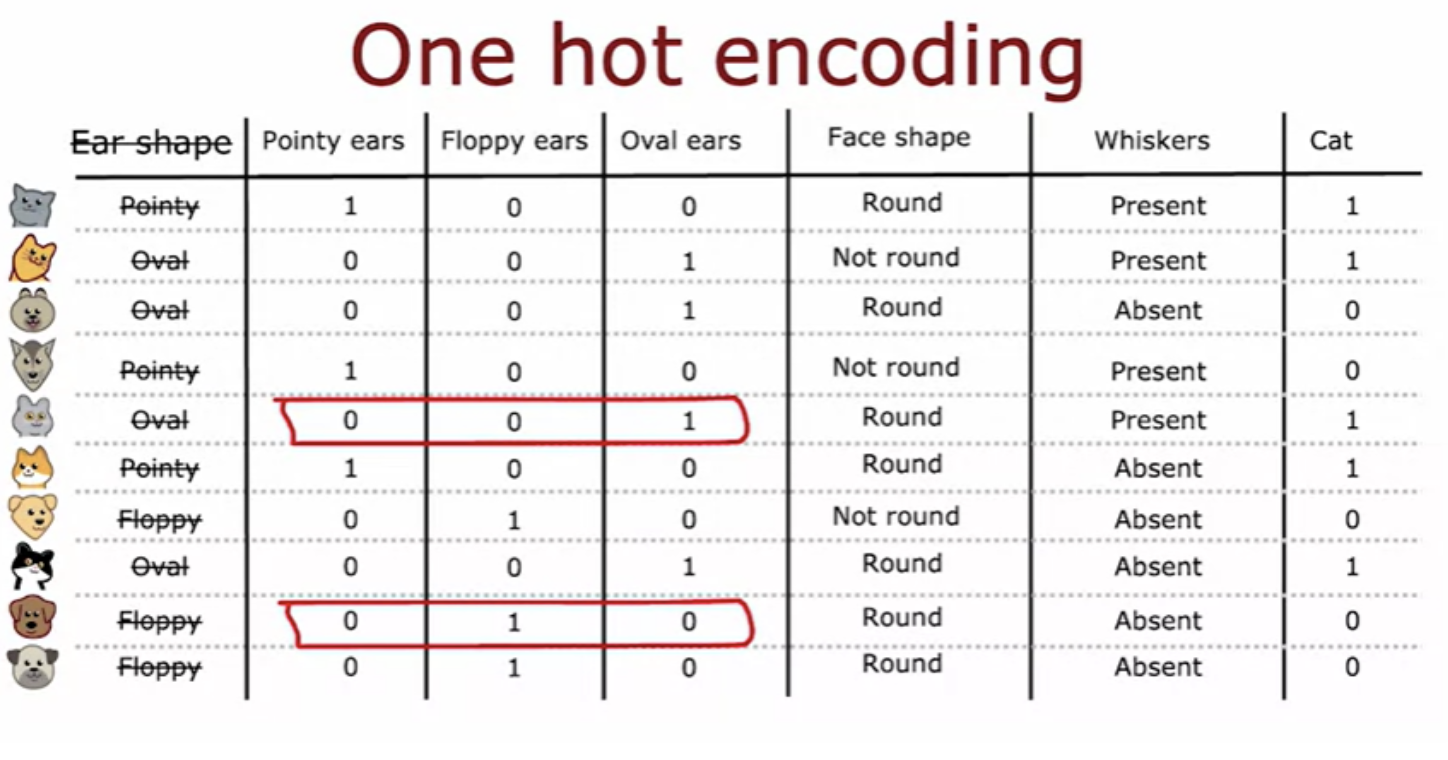
Rather than using an ear shaped feature, they can take on any of three possible values. We're going to create three new features where one feature is, does this animal have pointy ears, a second is does their floppy ears and the third is does it have oval ears. If you look at any role here, exactly 1 of the values is equal to 1. And that's what gives this method of future construction the name one-hot encoding. One of these features will always take on the value 1 that's the hot feature and hence the name one-hot encoding
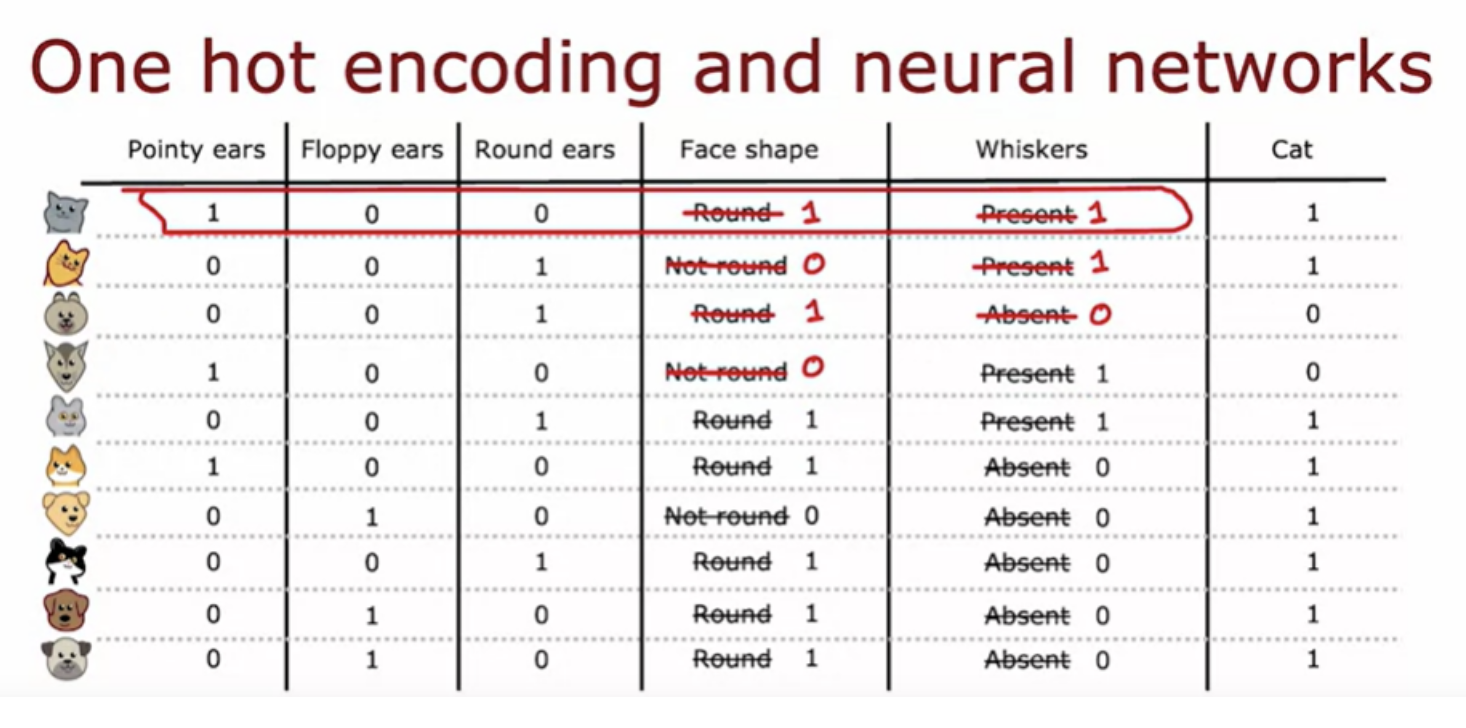
one-hot encoding is a technique that works not just for decision tree learning but also lets you encode categorical features using ones and zeros, so that it can be fed as inputs to a neural network as well which expects numbers as inputs
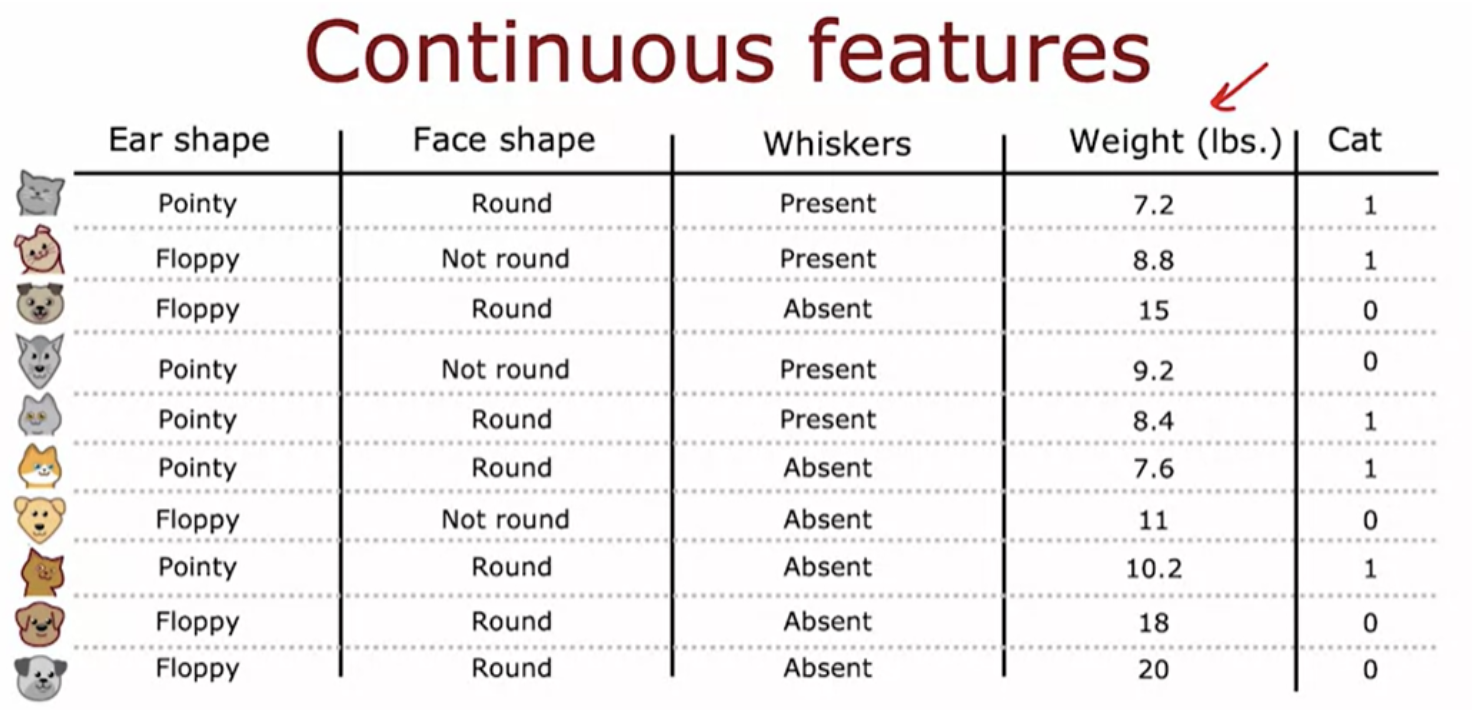
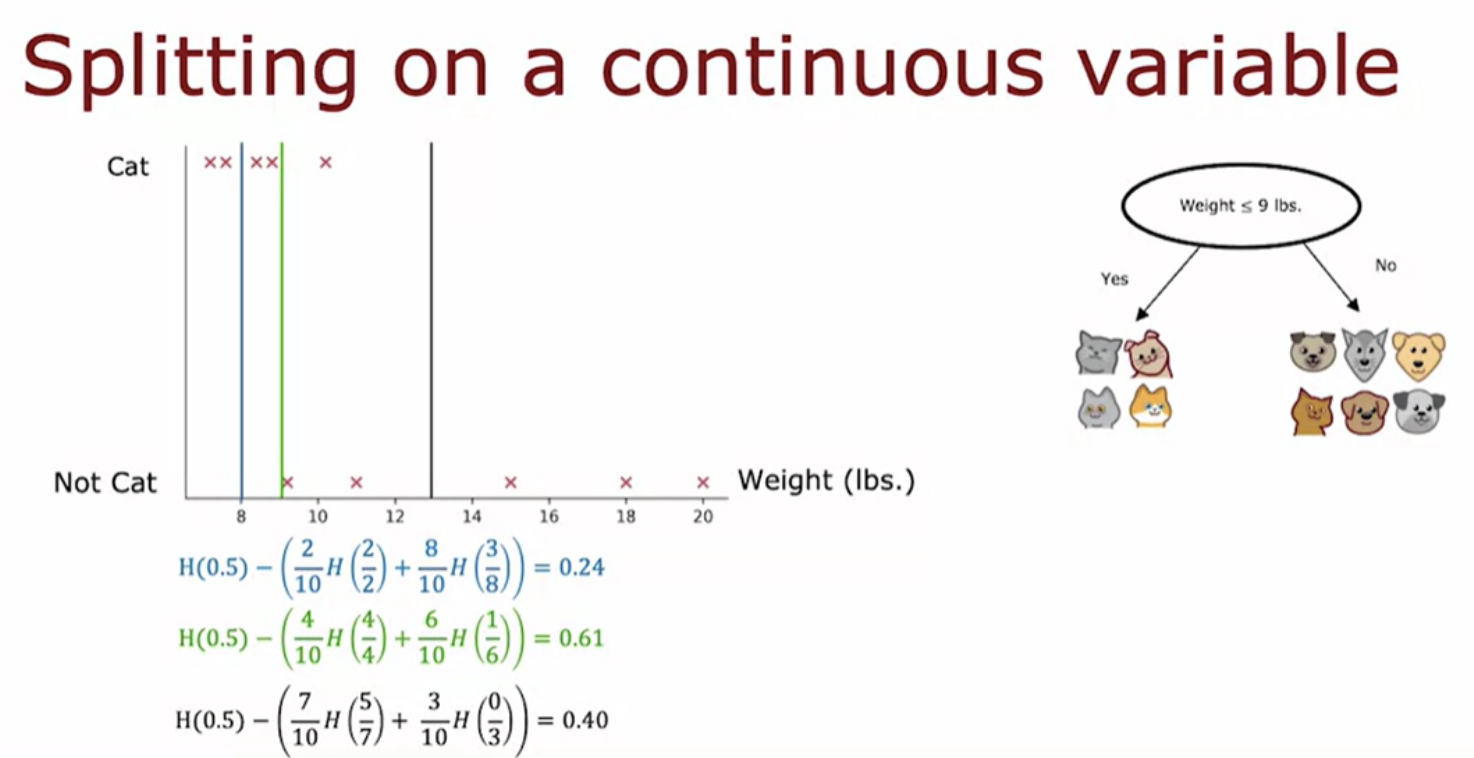
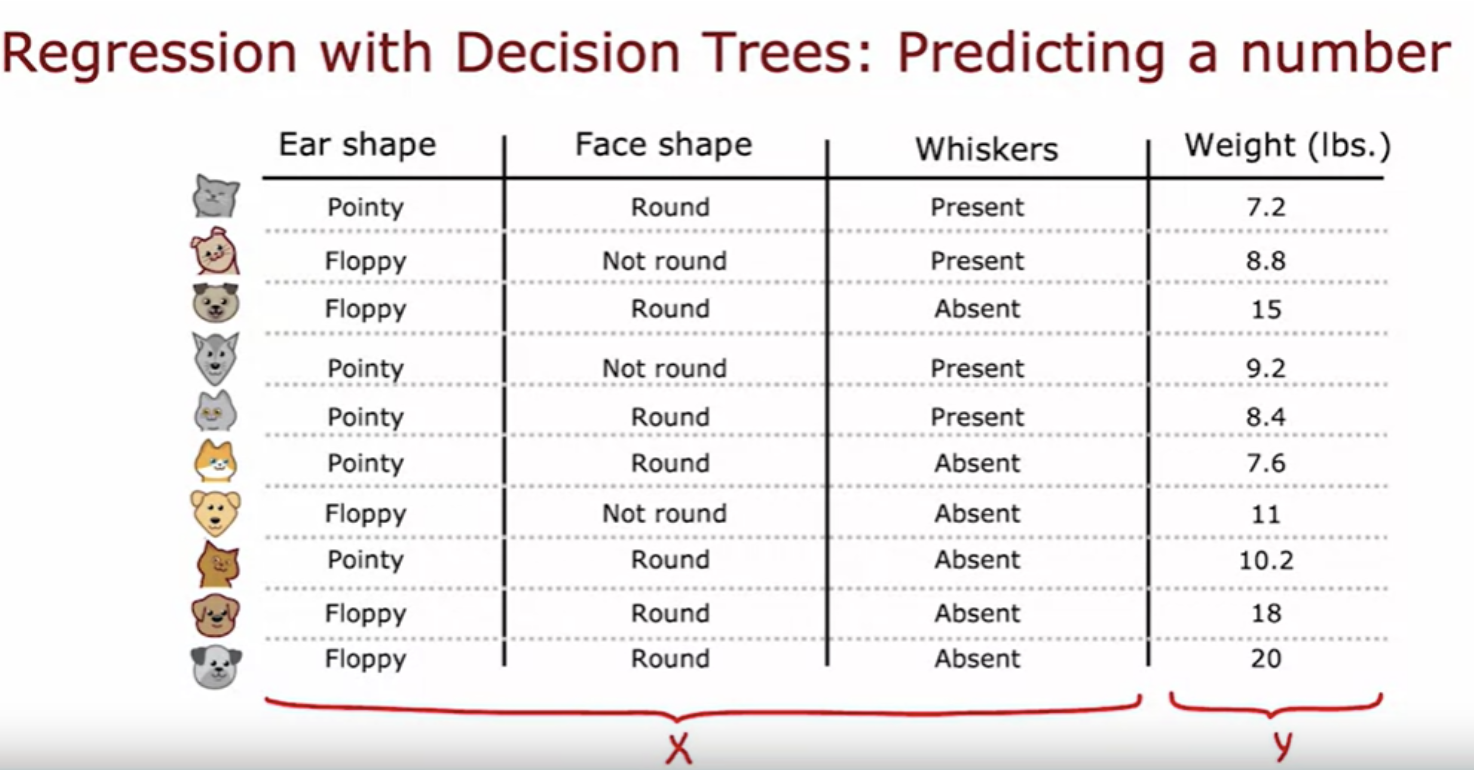
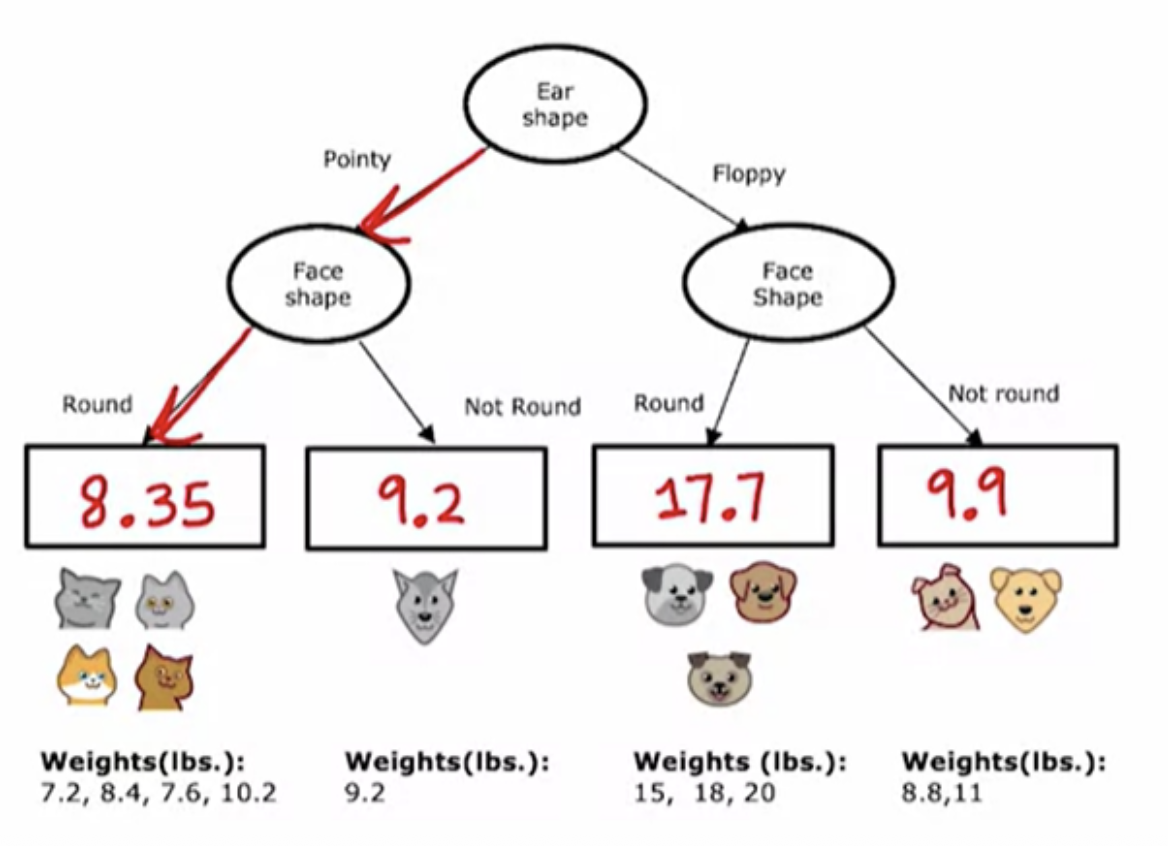
We can generalize decision trees to be regression algorithms, so that we can predict a number

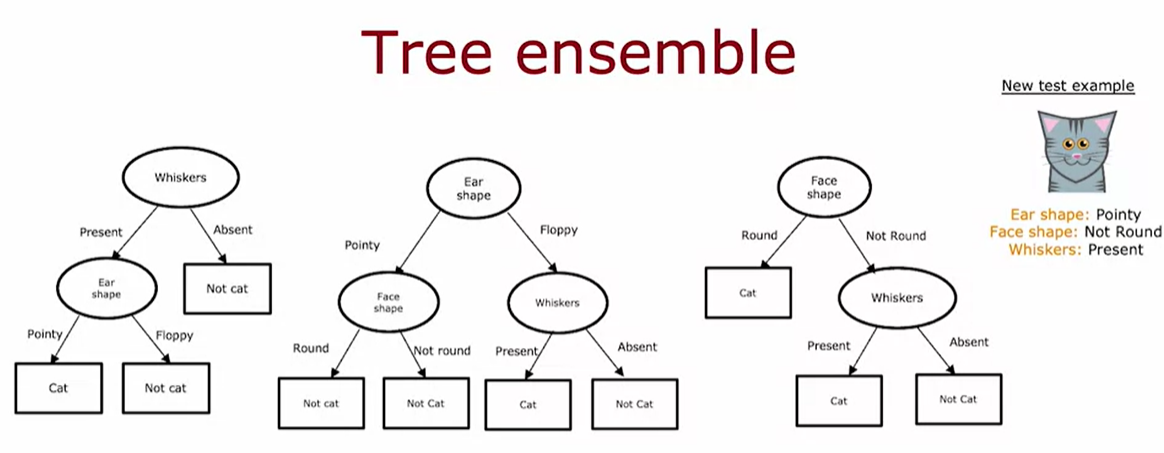
One of the weaknesses of using a single decision tree is that that decision tree can be highly sensitive to small changes in the data. One solution to make the algorithm less sensitive or more robust is to build not one decision tree, but to build a lot of decision trees, and we call that a tree ensemble.
The fact that changing just one training example causes the algorithm to come up with a different split at the root and therefore a totally different tree, that makes decision trees algorithm not that robust
Tree ensemble is means a collection of multiple trees.
In order to build a tree ensemble we need a technique called sampling with replacement.
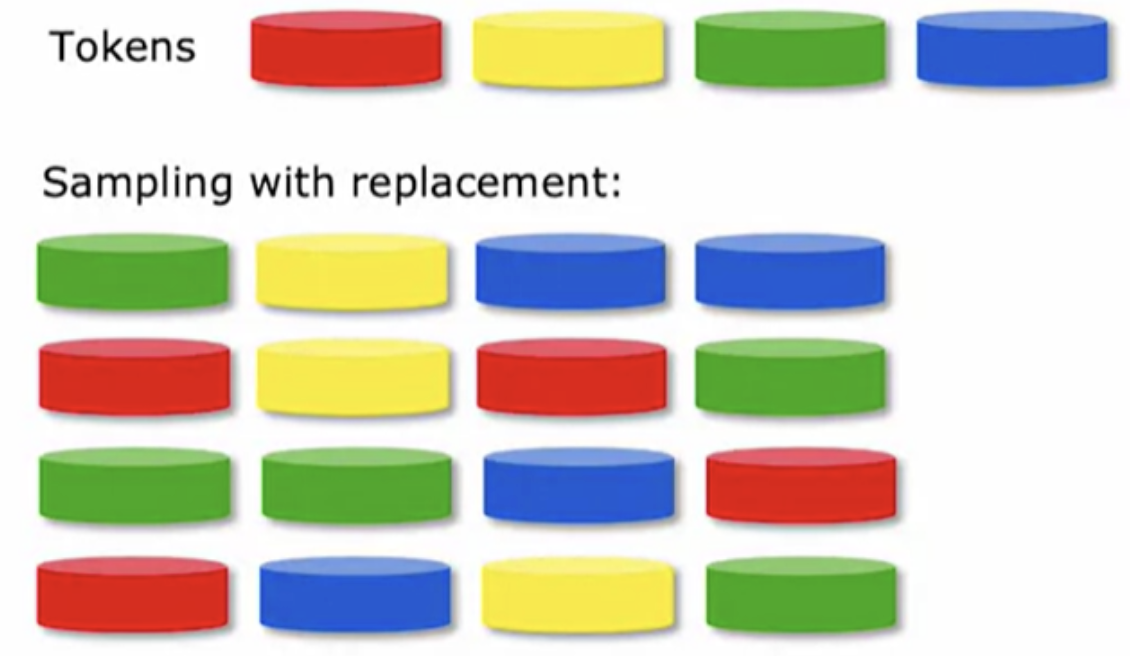
if we are not replacing a token every time we sample, then if we were to take four tokens from my bag of four, I will always just get the same four tokens. That's why replacing a token after we pull it out each time, is important to make sure we don't just get the same four tokens every single time.
Use sampling with replacement to create new training sets
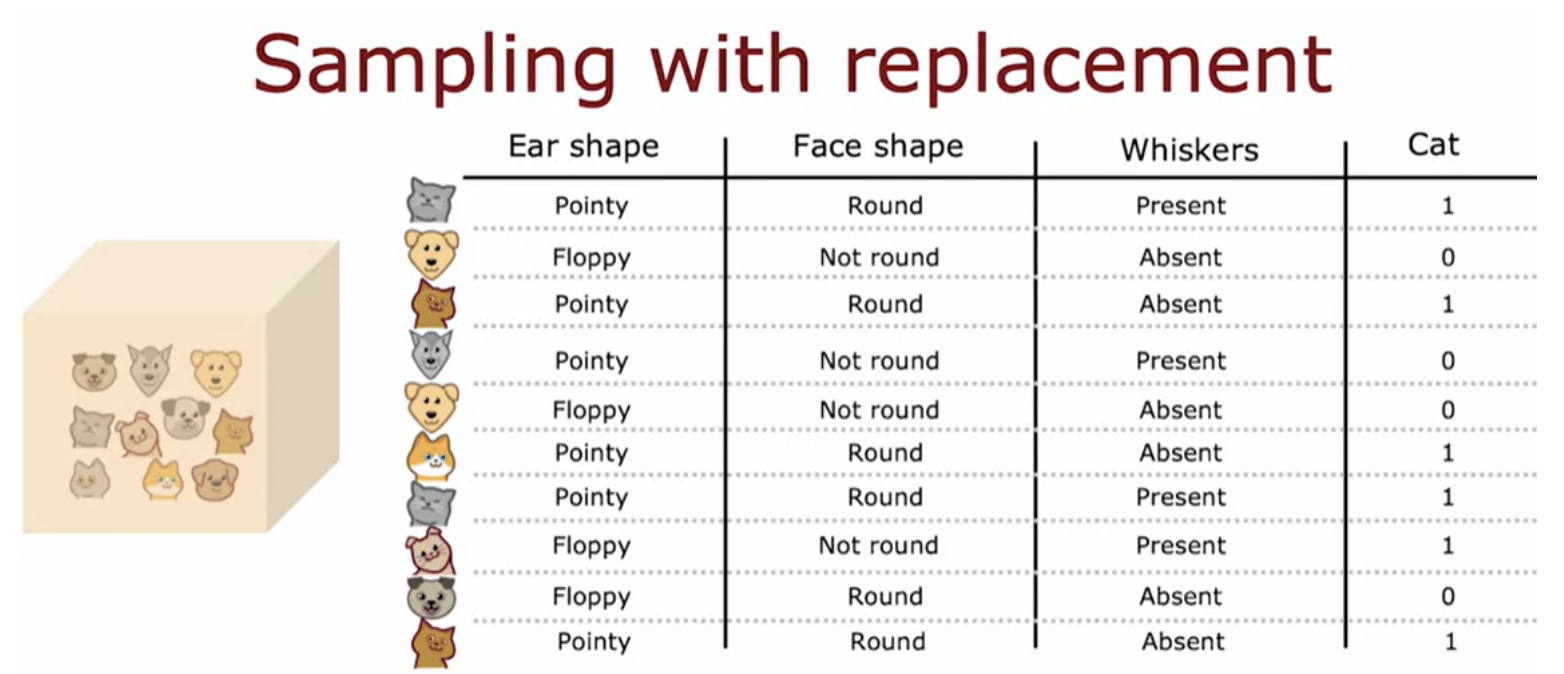
Random forest algorithm is a powerful tree ensamble algorithm that works much better than using a single decision tree.
Over the years, machine learning researchers have come up with a lot of different ways to build decision trees and decision tree ensembles. Today by far the most commonly used way or implementation of decision tree ensembles or decision trees there's an algorithm called XGBoost. It runs quickly, the open source implementations are easily used. And one of the innovations in XGBoost is that it also has built in regularization to prevent overfitting. The details of XGBoost are quite complex to implement, which is why many practitioners will use the open source libraries that implement XGBoost.

Both decision trees, including tree ensembles as well as neural networks are very powerful, very effective learning algorithms. Decision trees and tree ensembles will often work well on tabular data, also called structured data. What that means is if your dataset looks like a giant spreadsheet then Decision trees would be worth considering. decision trees and tree ensembles are not recommended on unstructured data. Examplease data such as images, video, audio, and texts that you're less likely to store in a spreadsheet format. Neural networks work better for unstructured data task.
One huge advantage of decision trees and tree ensembles is that they can be very fast to train
Small decision trees maybe human interpretable. If you are training just a single decision tree and that decision tree has only say a few dozen nodes you may be able to print out a decision tree to understand exactly how it's making decisions.
One slight downside of a tree ensemble is that it is a bit more expensive than a single decision tree
In contrast to decision trees and tree ensembles, neural networks works well on all types of data including tabular or structured data as well as unstructured data, and also on mixed data that includes both structured and unstructured components. On the downside though, neural networks may be slower than a decision tree.A large neural network can just take a long time to train. Other benefits of neural networks includes that it works with transfer learning and this is really important because for many applications we have only a small dataset being able to use transfer learning and carry out pre-training on a much larger dataset that is critical to getting competitive performance.

We learned supervised learning so far.
clustering algorithms is a way of grouping data into clusters, as well as anomaly detection.
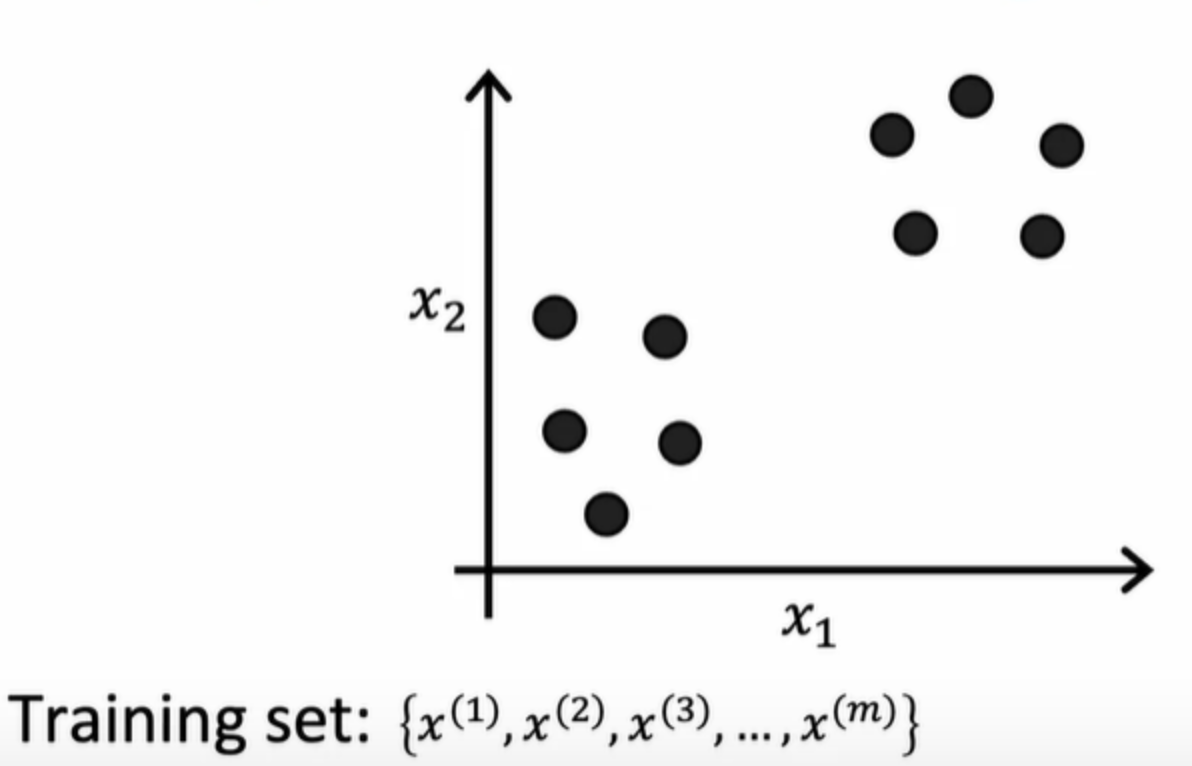
A clustering algorithm looks at a number of data points and automatically finds data points that are related or similar to each other. In unsupervised learning, you are given a dataset with just x, but not the labels or the target labels y.
Because we don't have target labels y, we're not able to tell the algorithm what is the right answer. Instead, we're going to ask the algorithm to find something interesting about the data. Clustering has also been used to analyze DNA data where you will look at the genetic expression data from different individuals and try to group them into people that exhibit similar traits.
plot a data set with 30 unlabeled training examples and randomly pick two points.
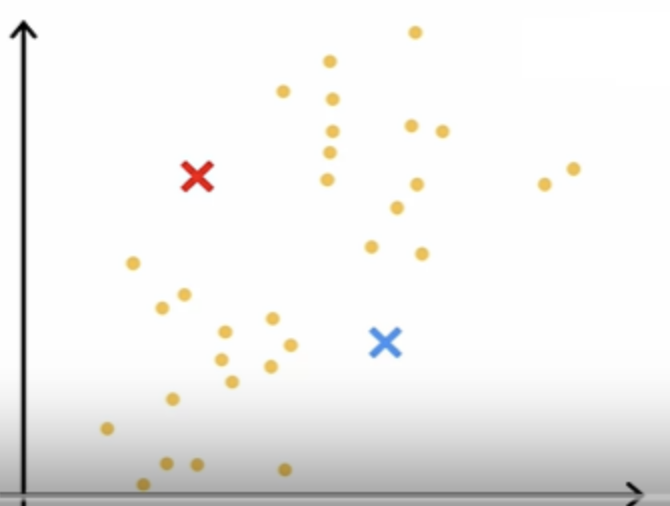
The centers of the cluster are called cluster centroids. After it's made an initial guess at where the cluster centroid is, it will go through all of these examples, x(1) through x(30). For each of them it will check if it is closer to the red cluster centroid or blue cluster centroid. And it will assign each of these points to whichever of the cluster centroids It is closer to. The take averge of red points, and average of blue points and move the red cross to whatever is the average location of the red dots.
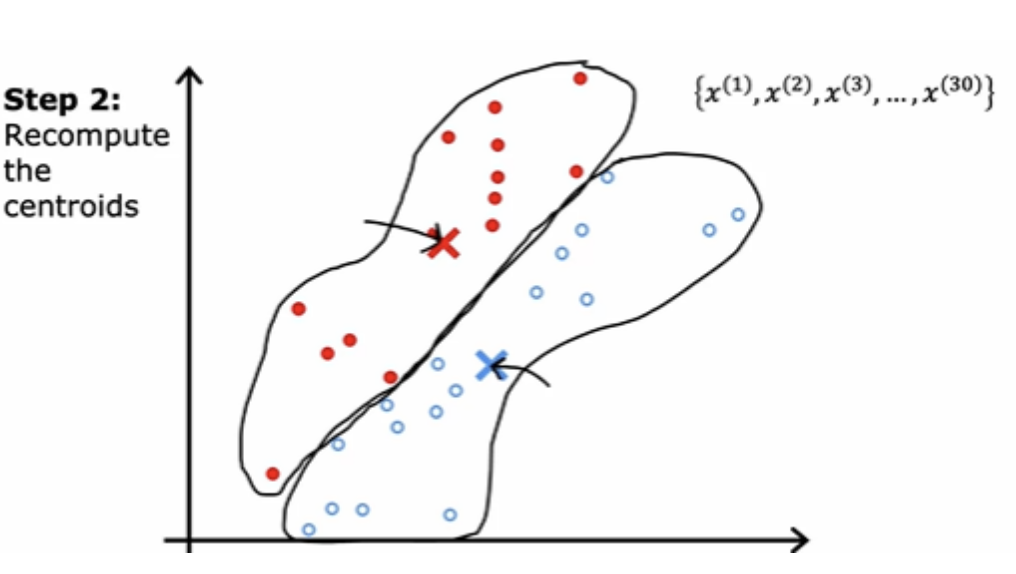
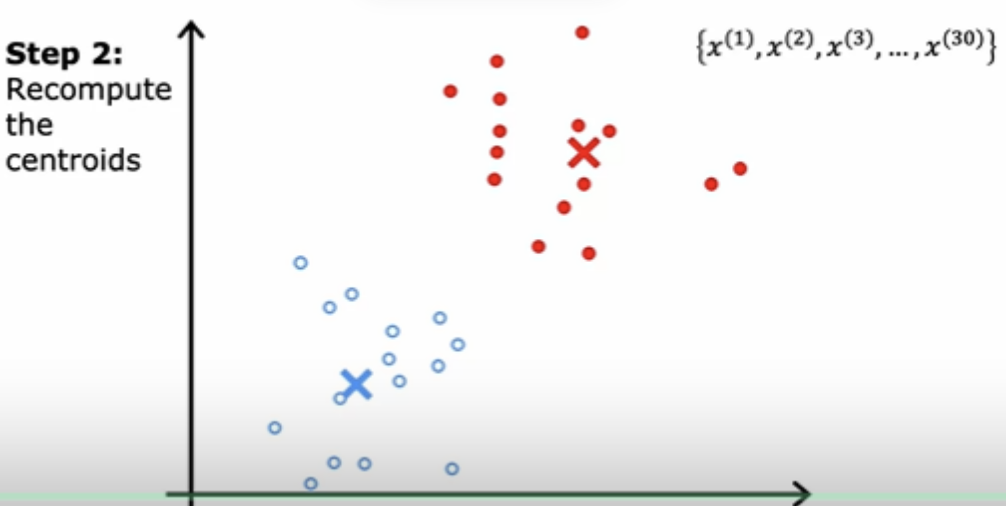
If you keep on doing those two steps, you find that there are no more changes to the colors of the points or to the locations of the clusters centroids. And this means that at this point the K-means clustering algorithm has converged
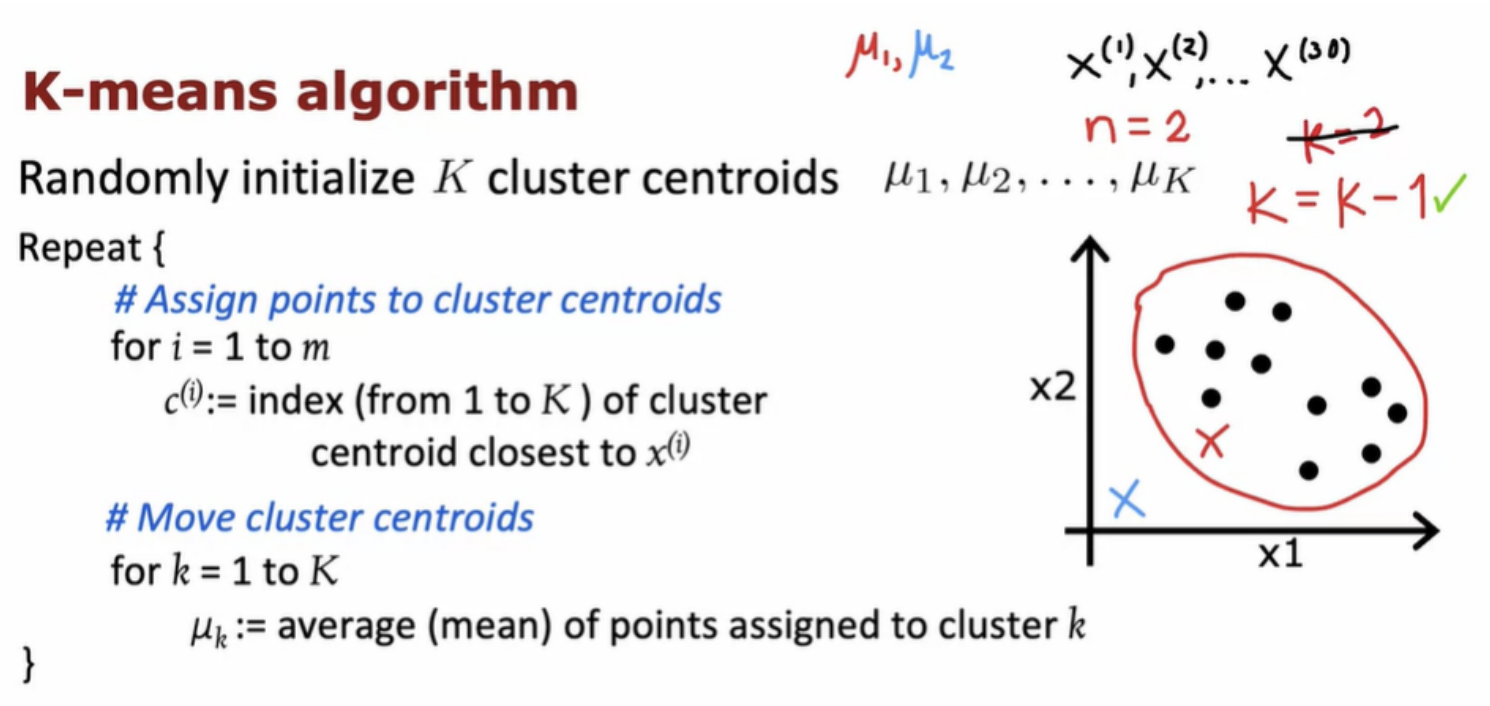

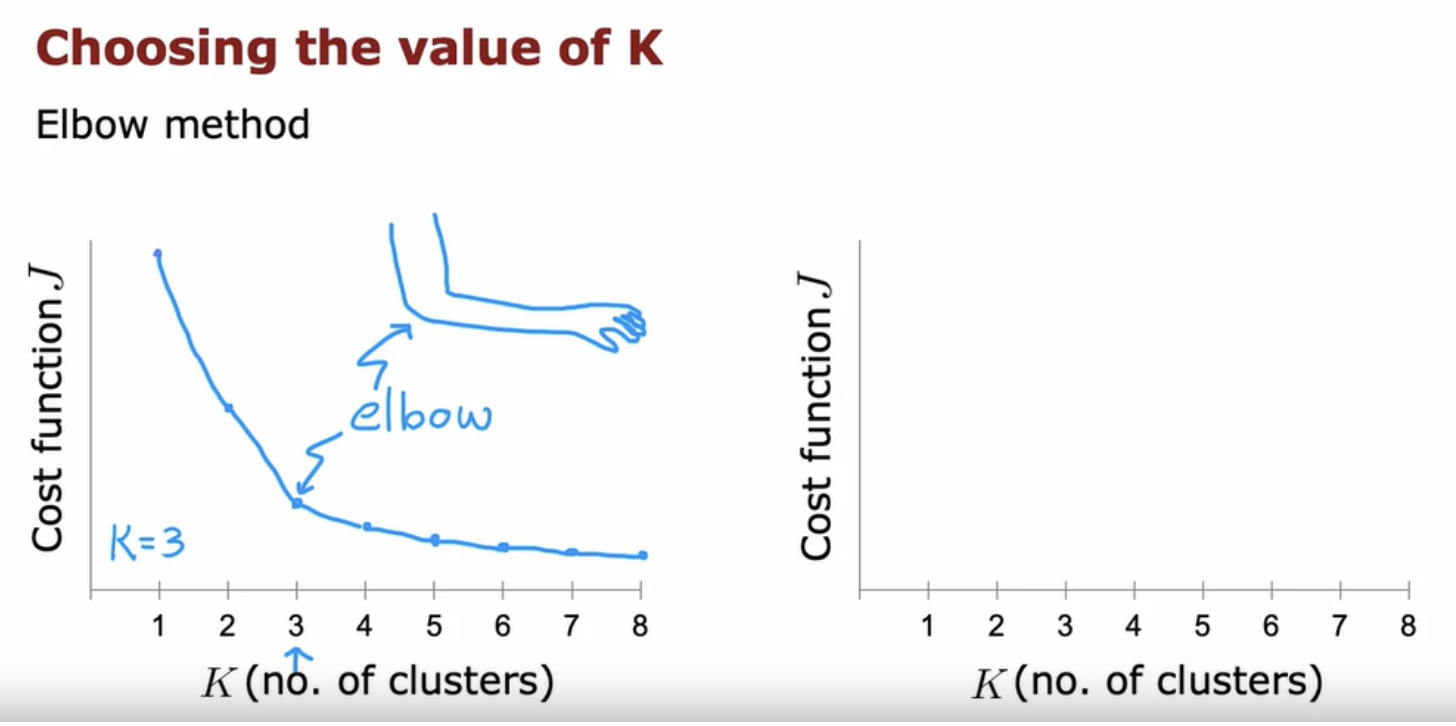
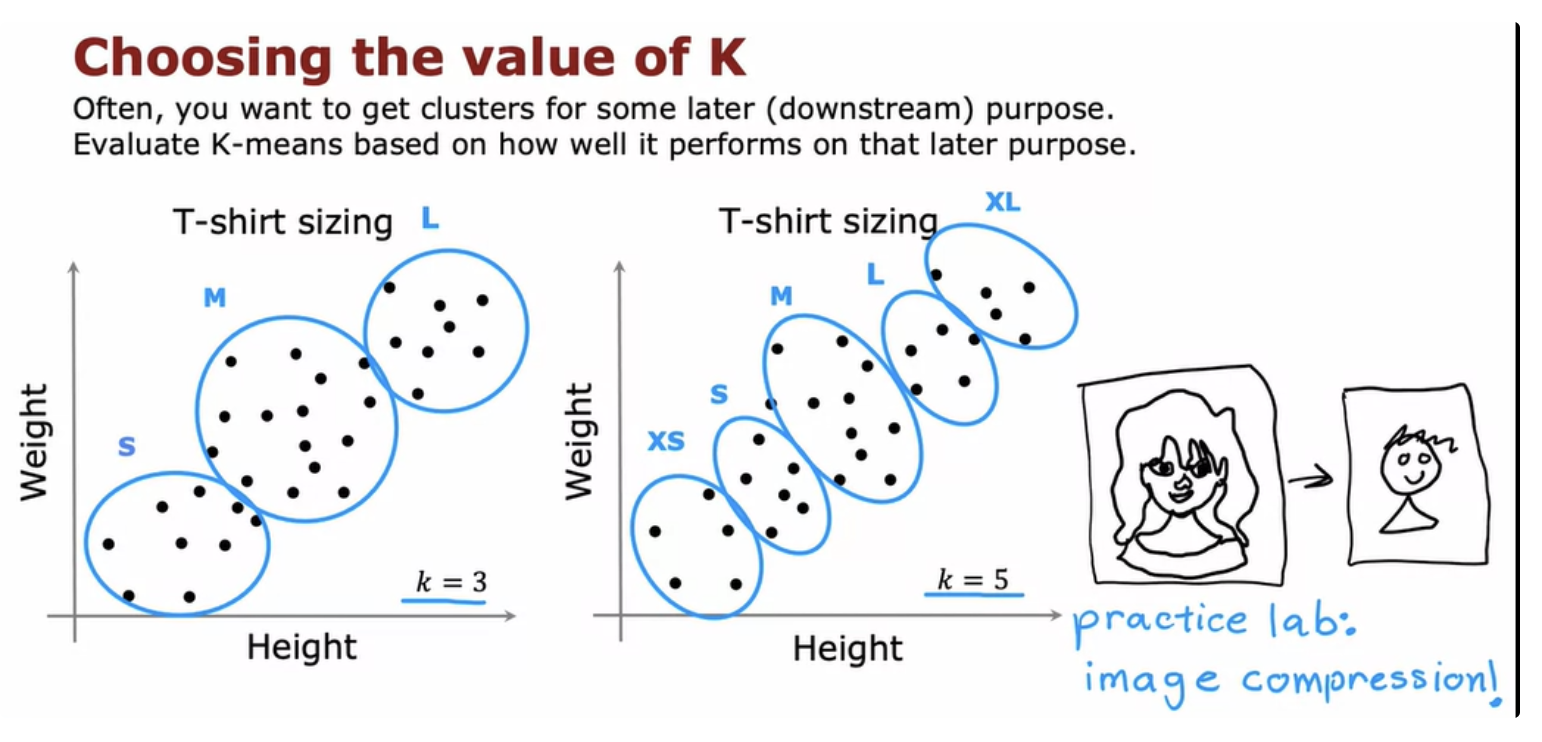
The k-means algorithm requires as one of its inputs, k, the number of clusters you want it to find. Because clustering is unsupervised learning algorithm you're not given the quote right answers in the form of specific labels to try to replicate. There are a few techniques to try to automatically choose the number of clusters to use for a certain application
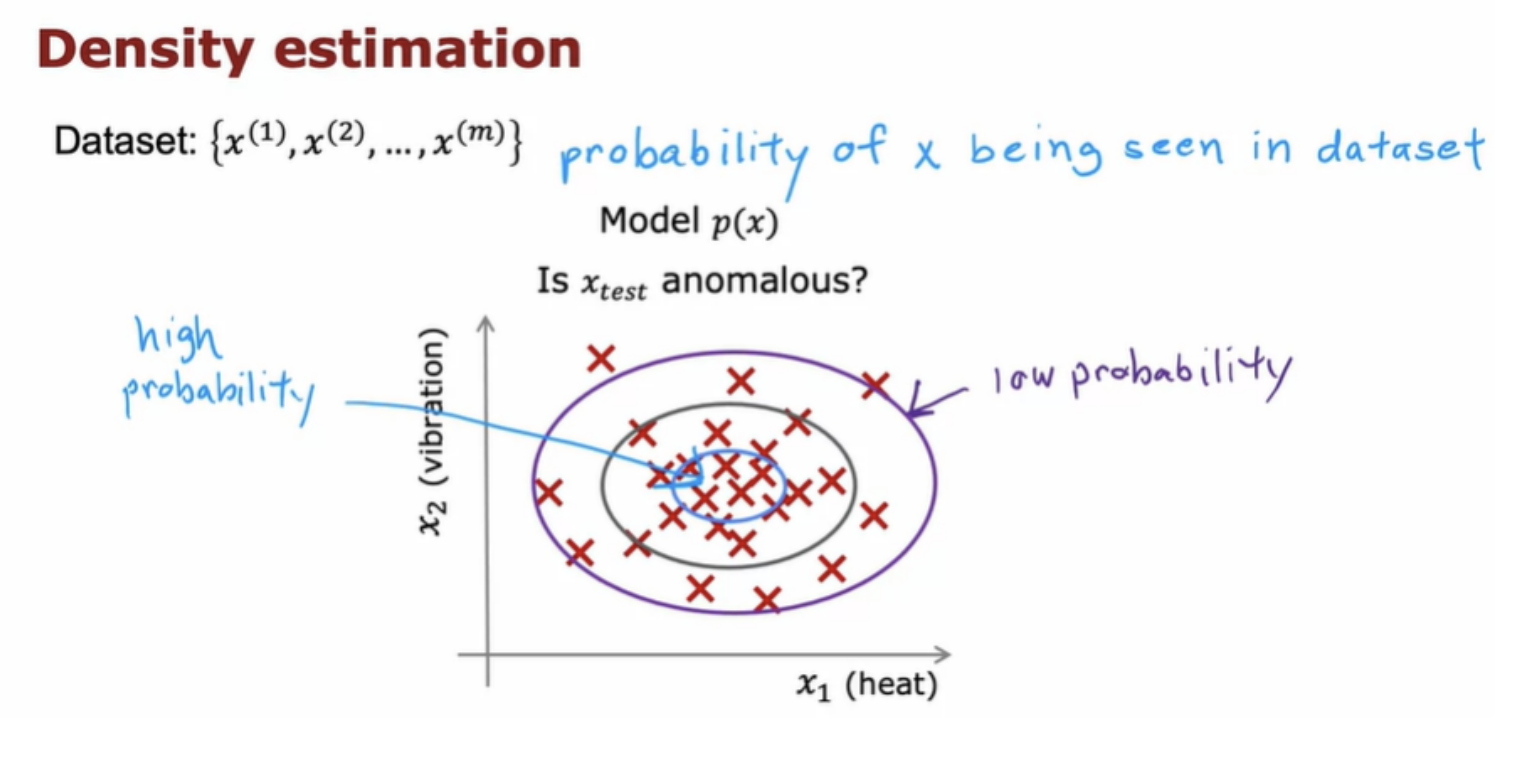
Anomaly detection algorithms look at an unlabeled dataset of normal events and thereby learns to detect or to raise a red flag for if there is an unusual or an anomalous event. Aircraft engines typically behave in terms of how much heat is generated and how much they vibrate. If a brand new aircraft engine were to roll off the assembly line and it had a new feature vector given by Xtest, we'd like to know does this engine look similar to ones that have been manufactured before.
The most common way to carry out anomaly detection is through a technique called density estimation.
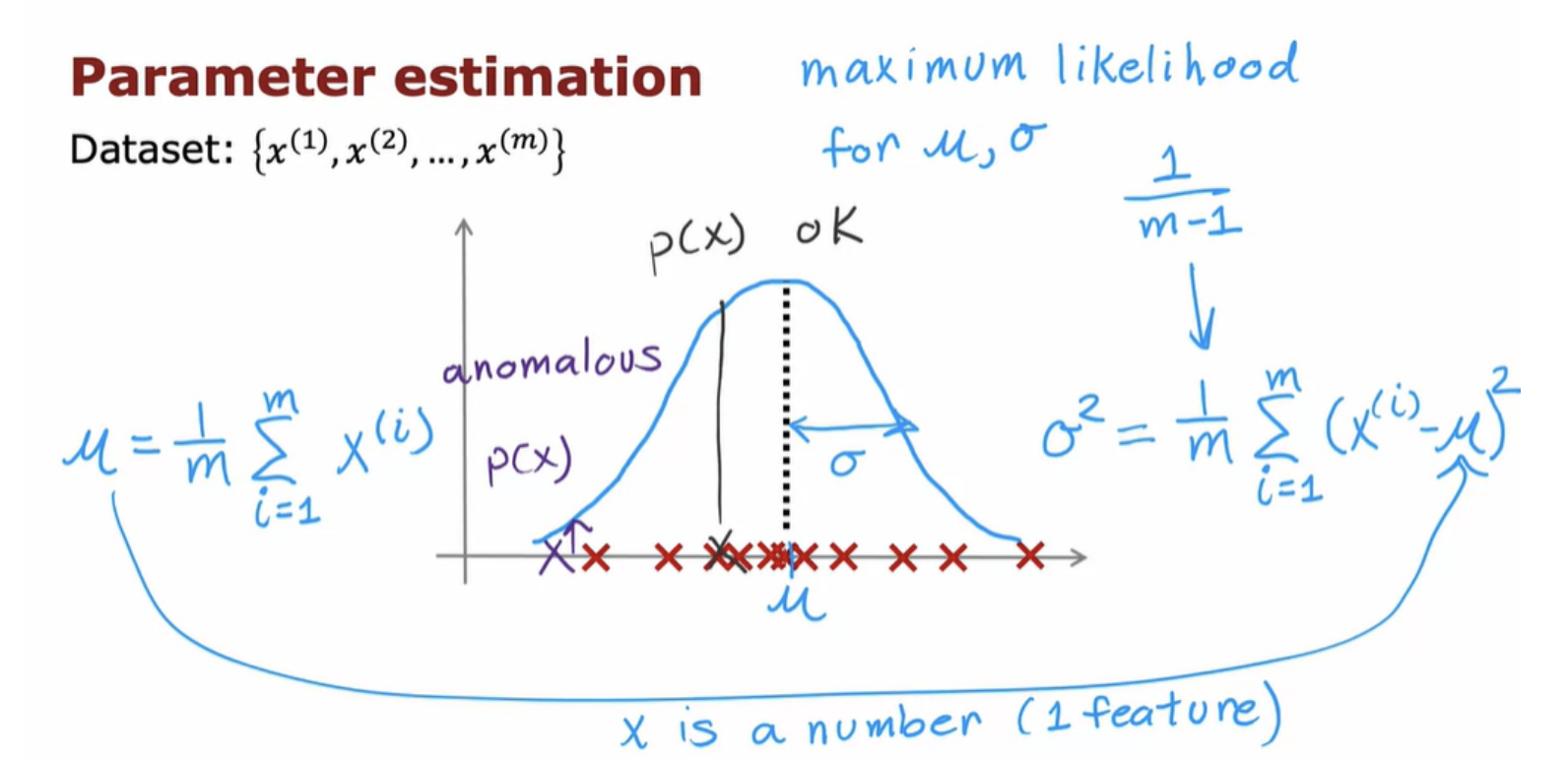
In order to get anonymous detection algorithms to work, we'll need to use a Gaussian distribution to model the data p (x).
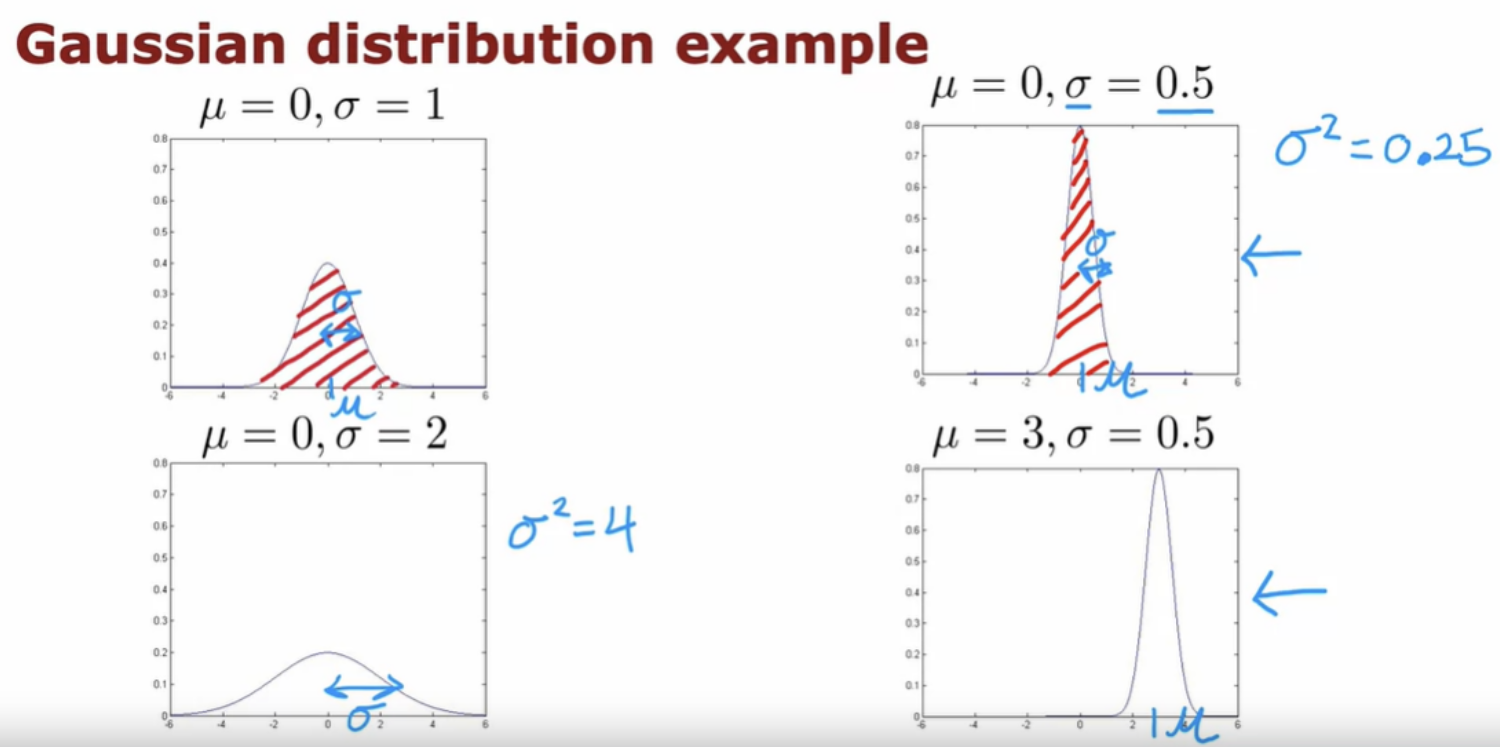
Gaussian distribution, normal distribution, bell-shaped distribution , all refers to the same thing.
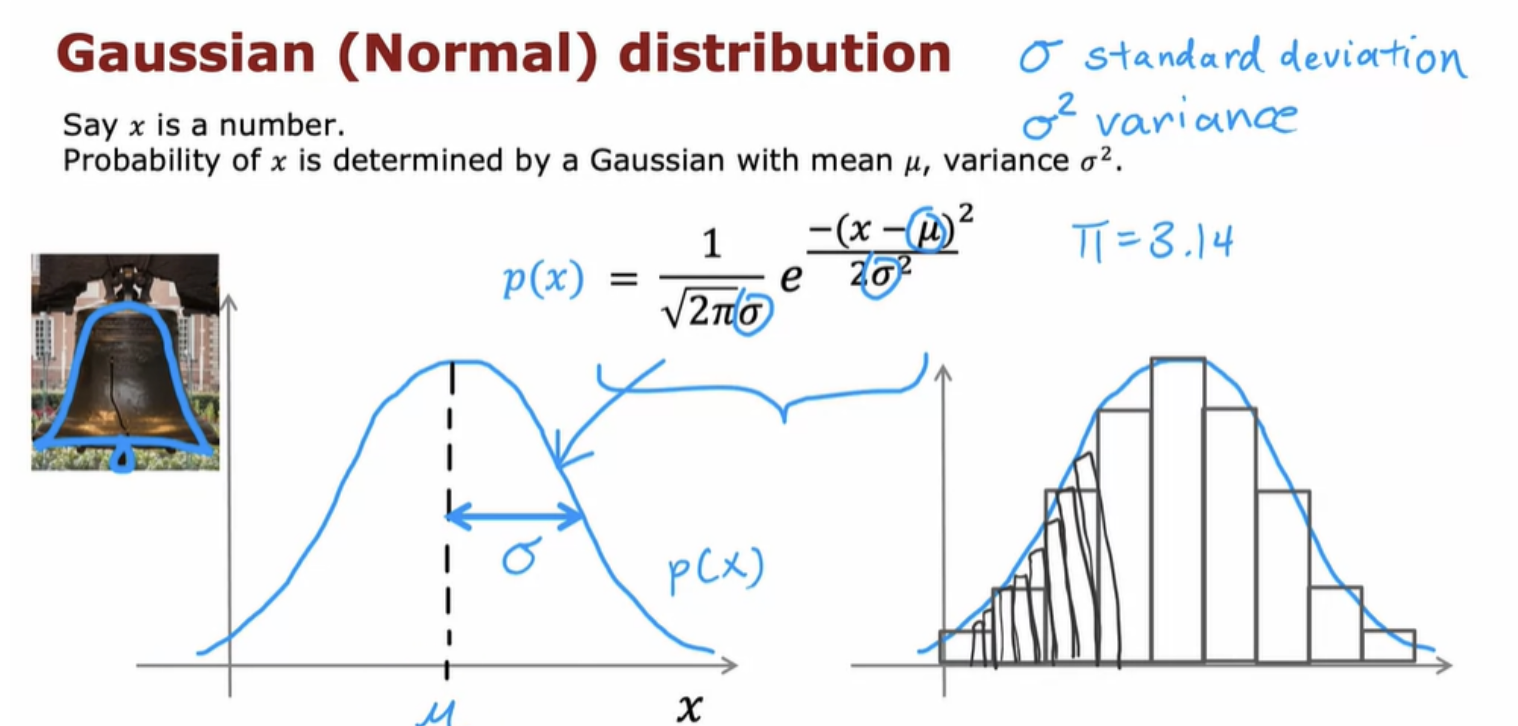
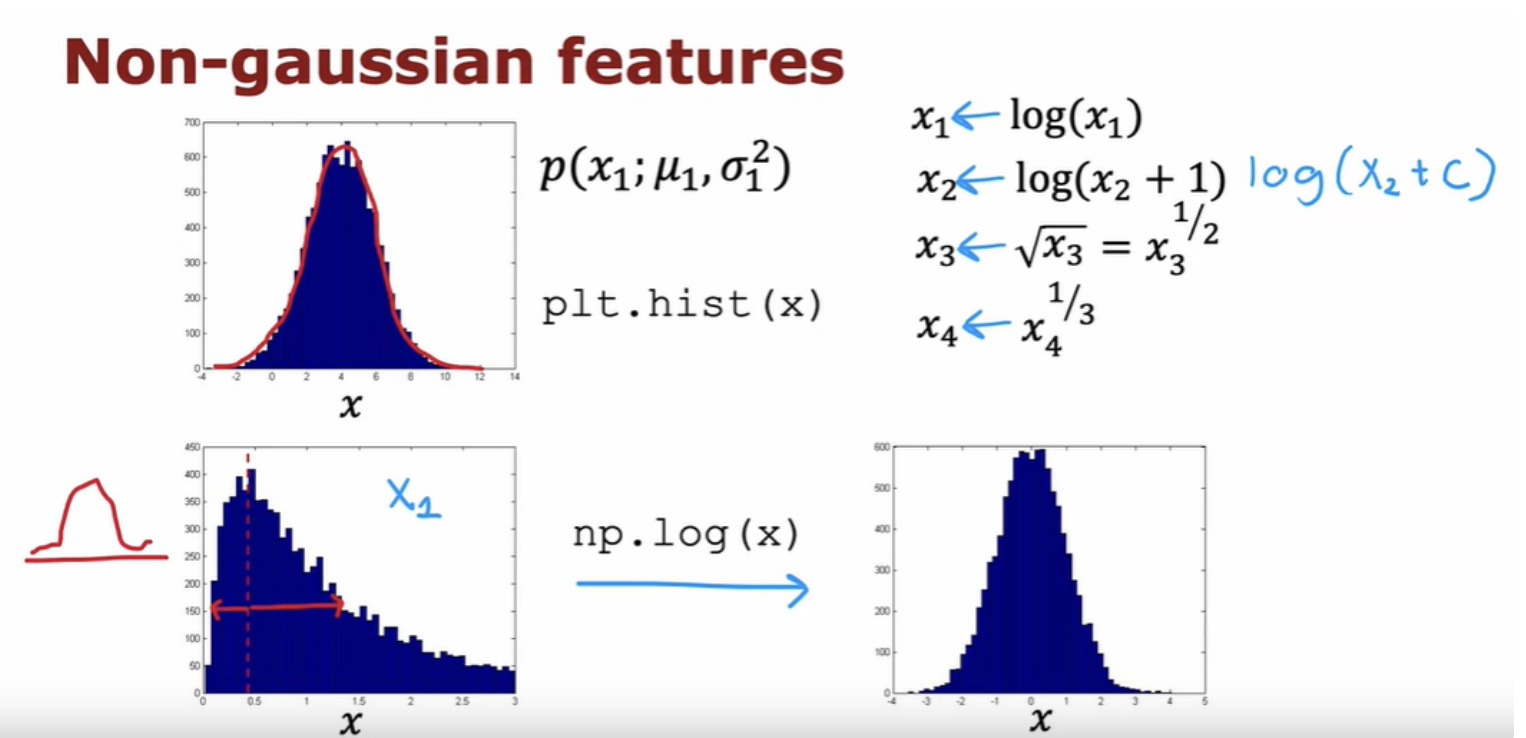
Let's look at a few examples of how changing Mu and Sigma will affect the Gaussian distribution. Probabilities always have to sum up to one, so that's why the area under the curve is always equal to one, which is why when the Gaussian distribution becomes skinnier, it has to become taller as well.
But for practical anomaly detection applications, you will have many features, two or three or some even larger number n of features.
Suppose for an aircraft engine there's a 1/10 chance that it is really hot, unusually hot and there is a 1 in 20 chance that it vibrates really hard. Then, what is the chance that it runs really hot and vibrates really hard ? The chance of that is 1/10 times 1/20 which is 1/200. So it's really unlikely to get an engine that both run really hot and vibrates really hard.


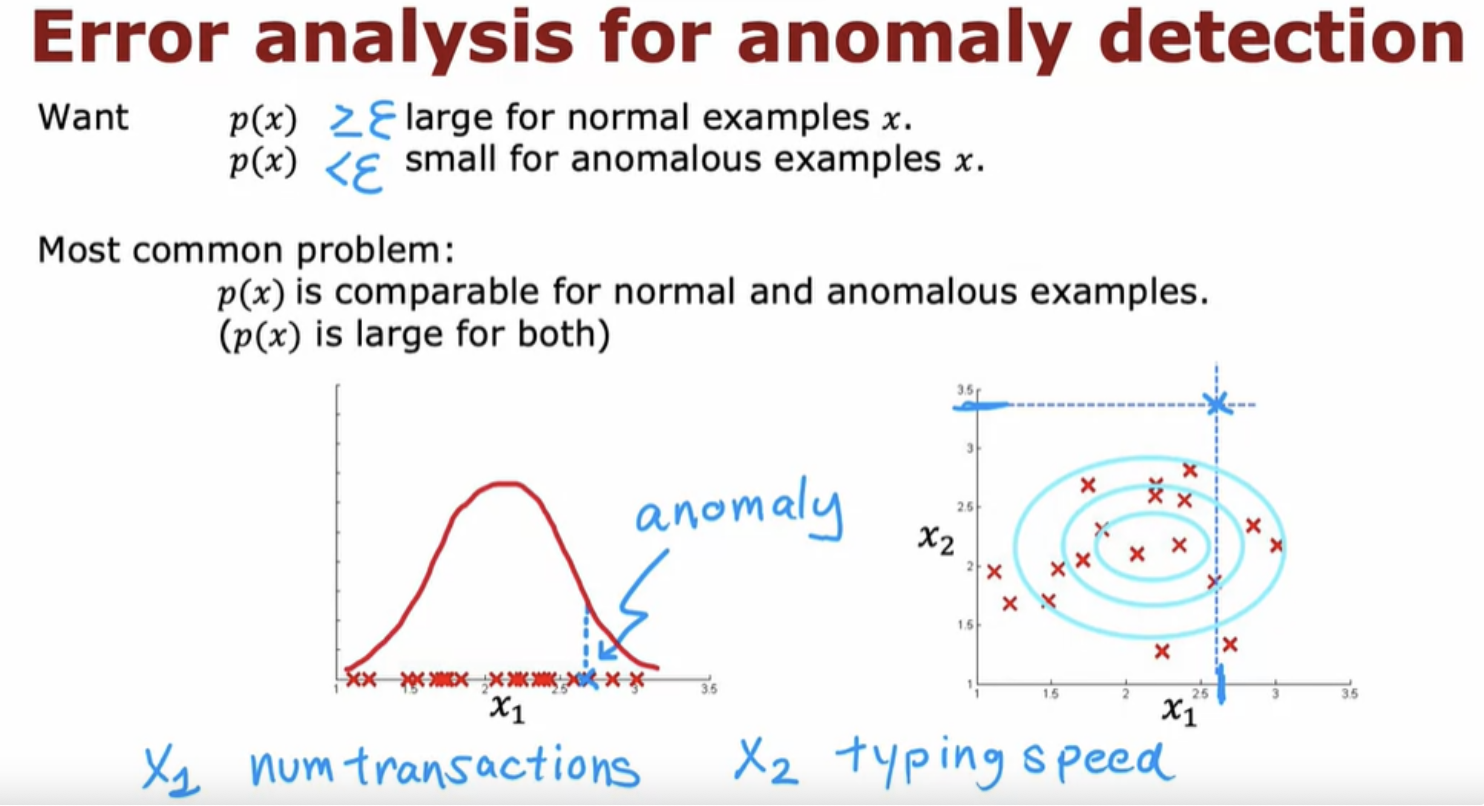
This algorithm is a systematic way of quantifying whether or not this new example x has any features that are unusually large or unusually small.
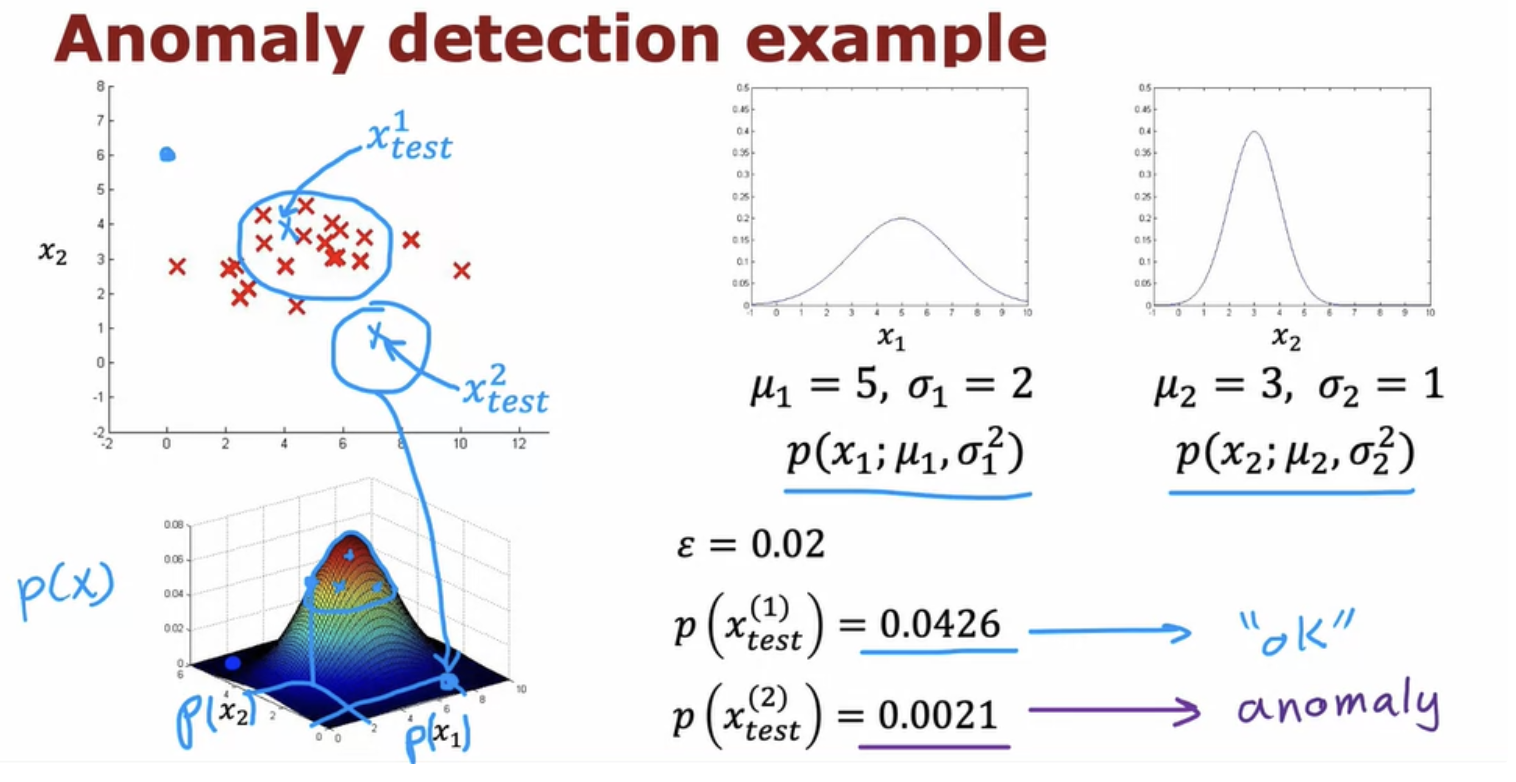

What anomaly detection does is it looks at the normal examples that is the y = 0 negative examples and just try to model what they look like. And anything that deviates a lot from normal It flags as an anomaly

Anomaly detection tries to find brand new positive examples that may be unlike anything you've seen before
In supervised learning, if you don't have the features quite right, or if you have a few extra features that are not relevant to the problem, that often turns out to be okay. But for anomaly detection which runs, or learns just from unlabeled data, is harder for the algorithm to figure out what features to ignore. One step that can help your anomaly detection algorithm, is to try to make sure the features you give it are more or less Gaussian.