
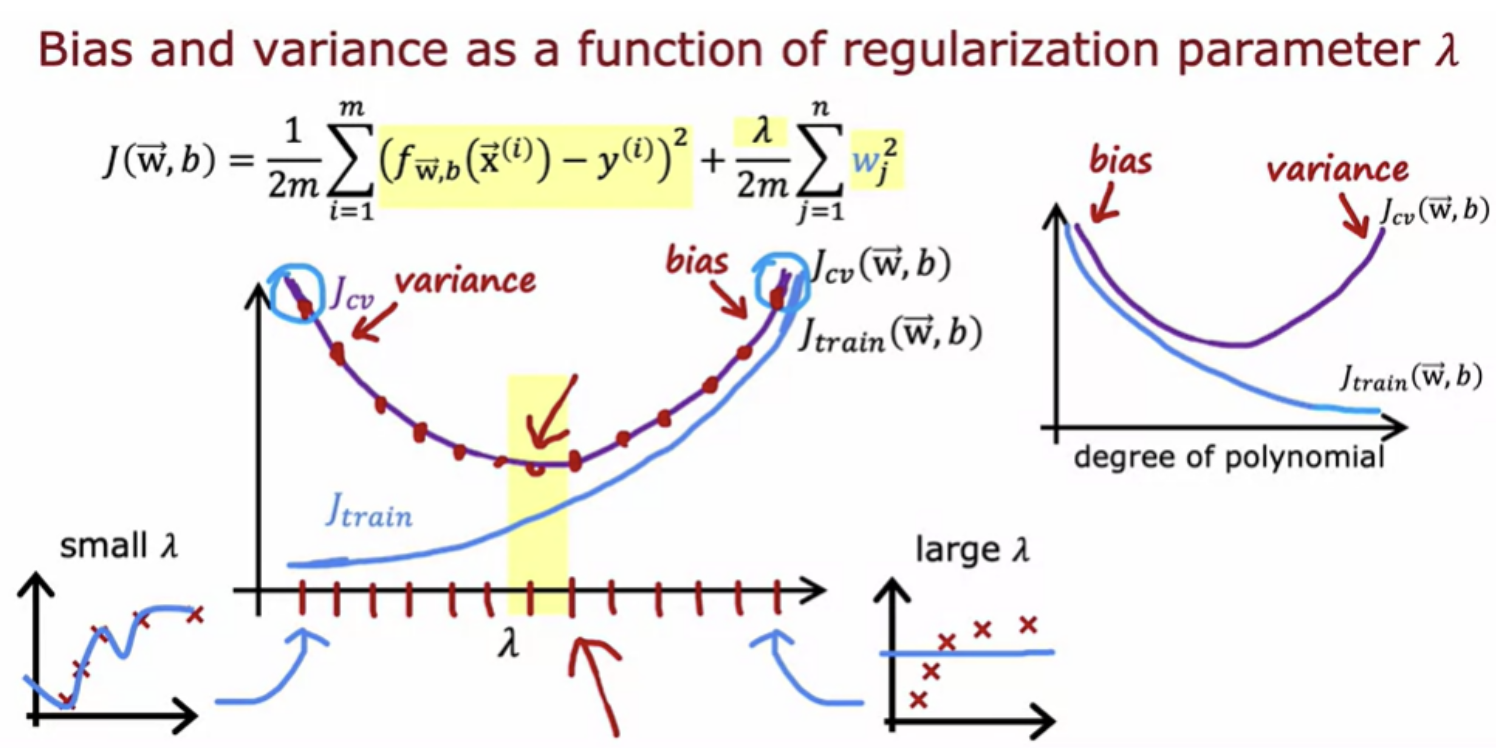
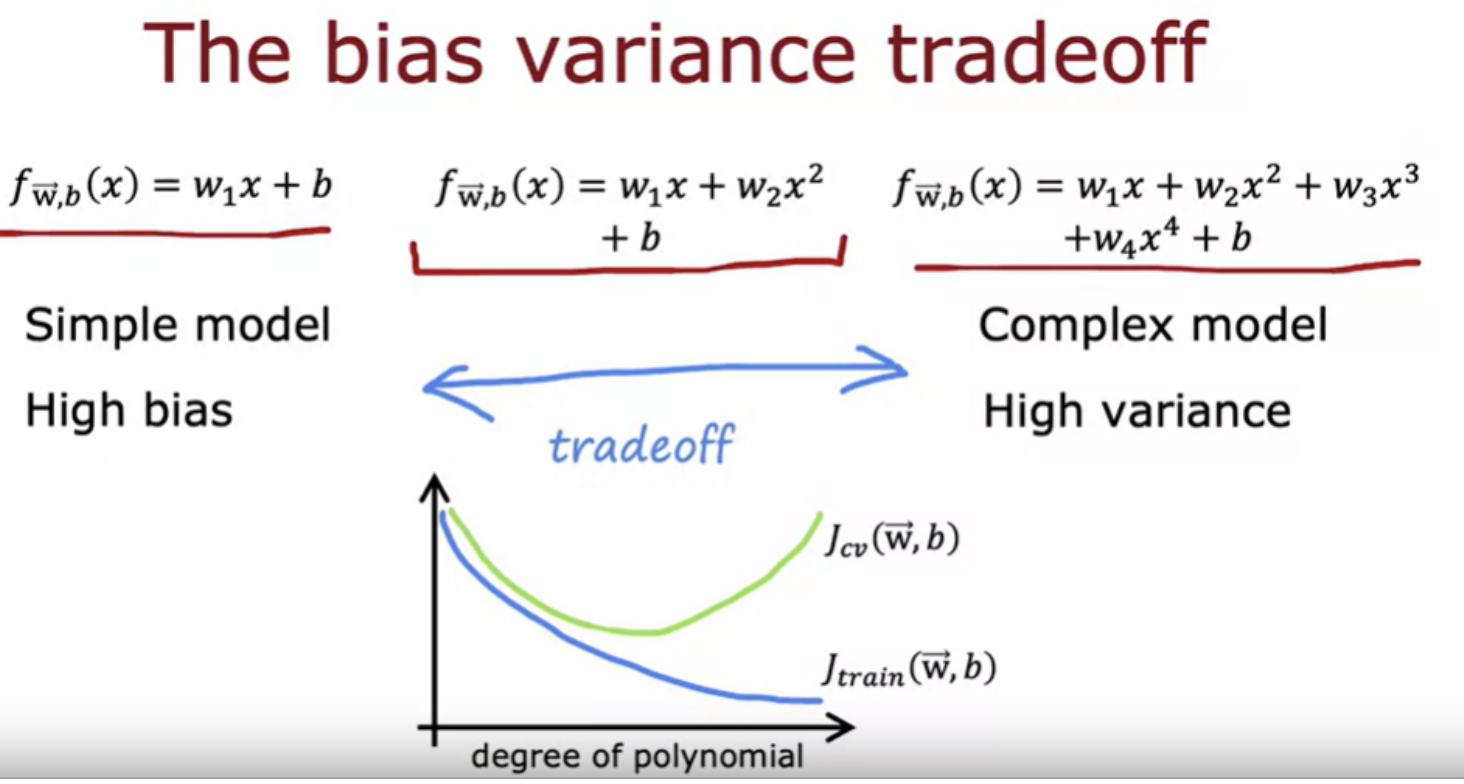
The choice of the regularization parameter Lambda affects the bias and variance and therefore the overall performance of the algorithm. Lambda is the regularization parameter that controls how much you trade-off keeping the parameters w small versus fitting the training data well.

Learning curves are a way to help understand how your learning algorithm is doing as a function of the amount of experience (number of training examples) it has

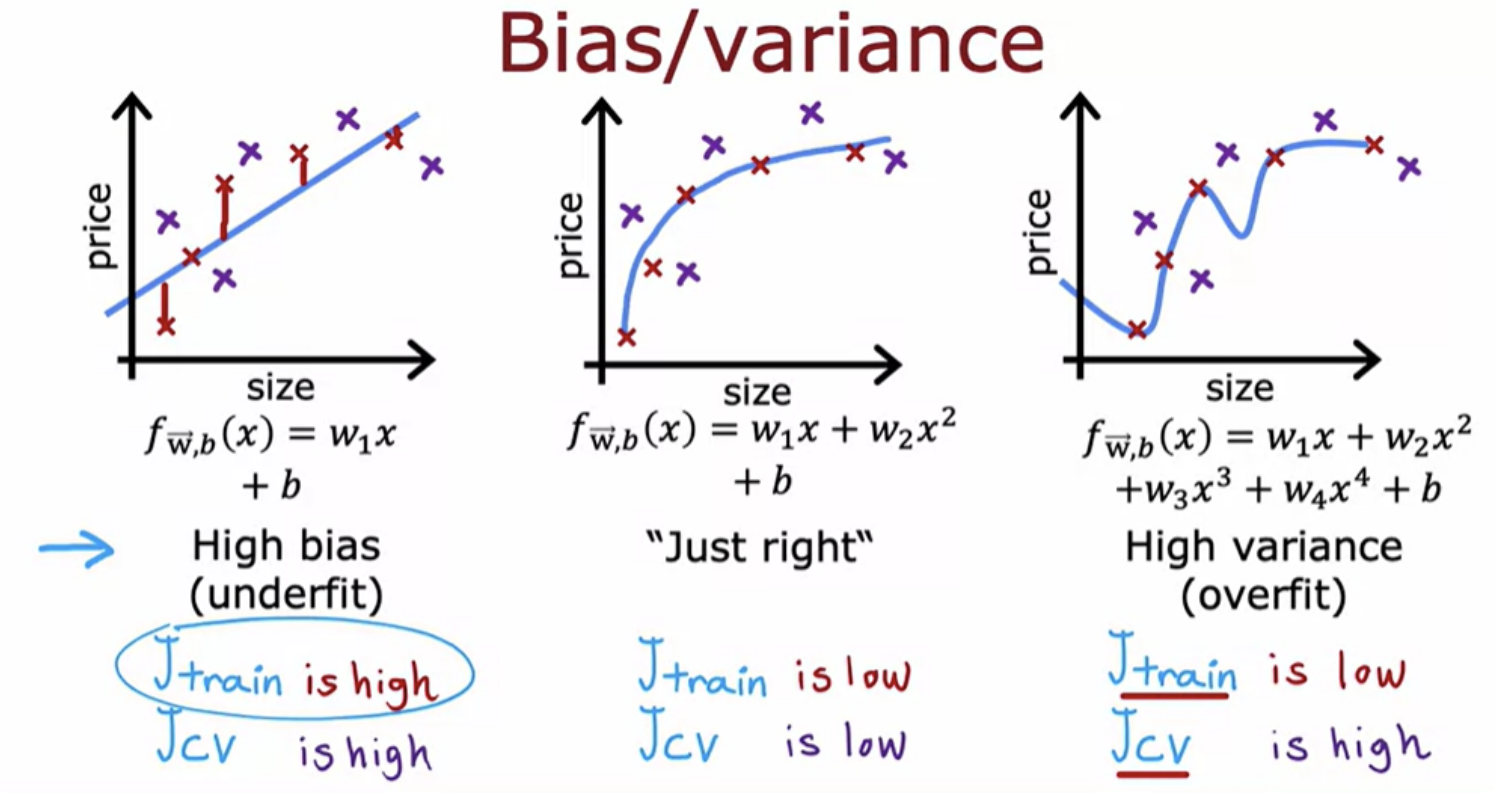
Training set error and cross-validation error are two important metrics used to evaluate how well a model is performing. Training Set Error - The error the model makes on the same data it was trained on. Cross-Validation Error - The error the model makes on unseen data, typically estimated by techniques like k-fold cross-validation.
A the training set size gets bigger, the cross-validation error goes down.and the training set error actually increases.
when you have a very small number of training examples like one or two or even three, is relatively easy to get zero or very small training error, but when you have a larger training set is harder for quadratic function to fit all the training examples perfectly. Which is why as the training set gets bigger, the training error increases because it's harder to fit all of the training examples perfectly.
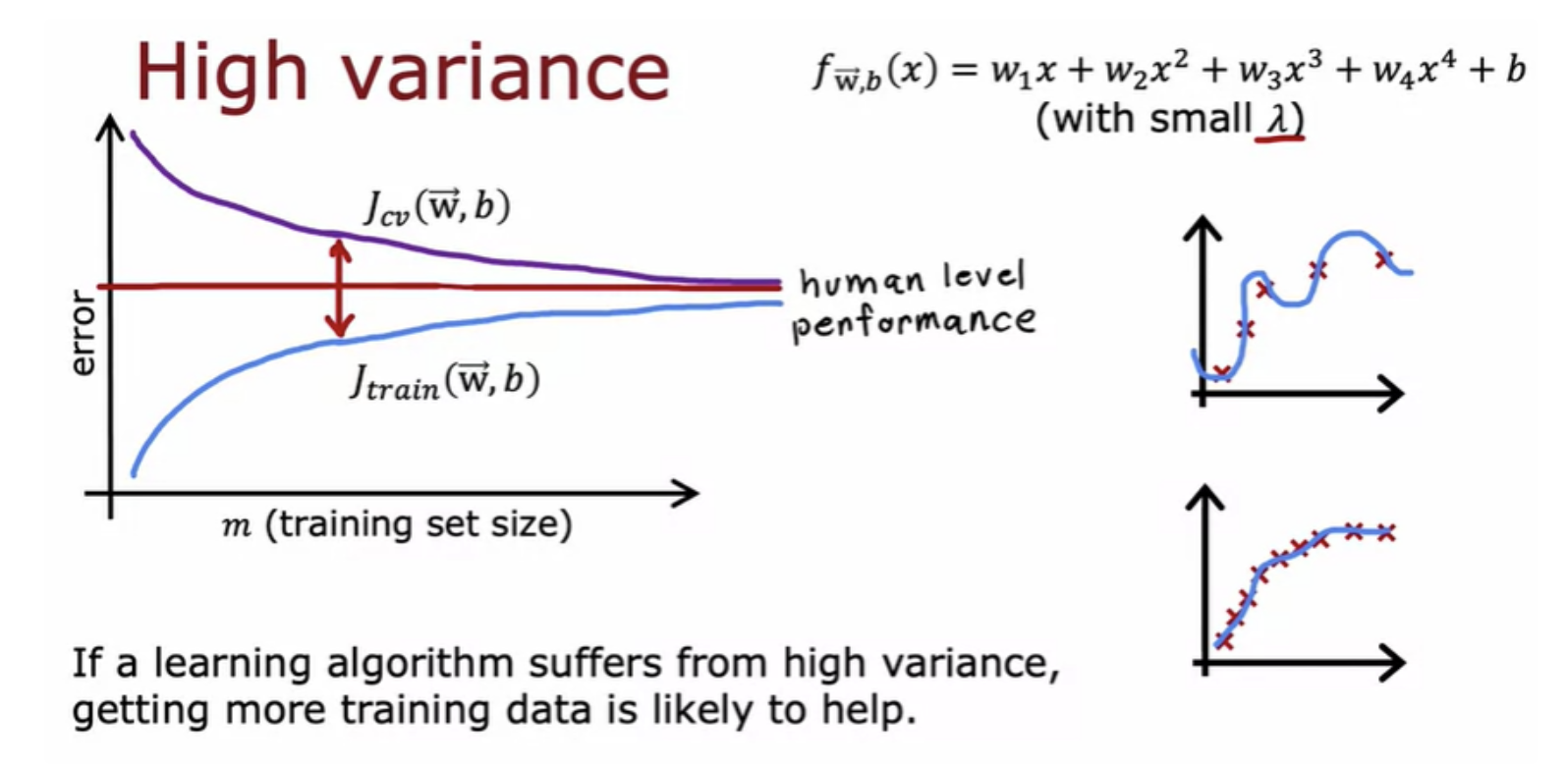
If you're building a machine learning application, you could plot the learning curves . You can take different subsets of your training sets. Even if you have, say, 1,000 training examples, you could train a model on just 100 training examples and look at the training error and cross-validation error, then train a model on 200 examples, holding out 800 examples and without using them for now.
If you find that your algorithm has high variance, then the two main ways to fix that are - either get more training data or simplify your model (get a smaller set of features or increase the regularization parameter Lambda)
If your algorithm has high bias, then that means is not doing well even on the training set. If that's the case, the main fixes are to make your model more powerful or to give them more flexibility to fit more complex or more wiggly functions
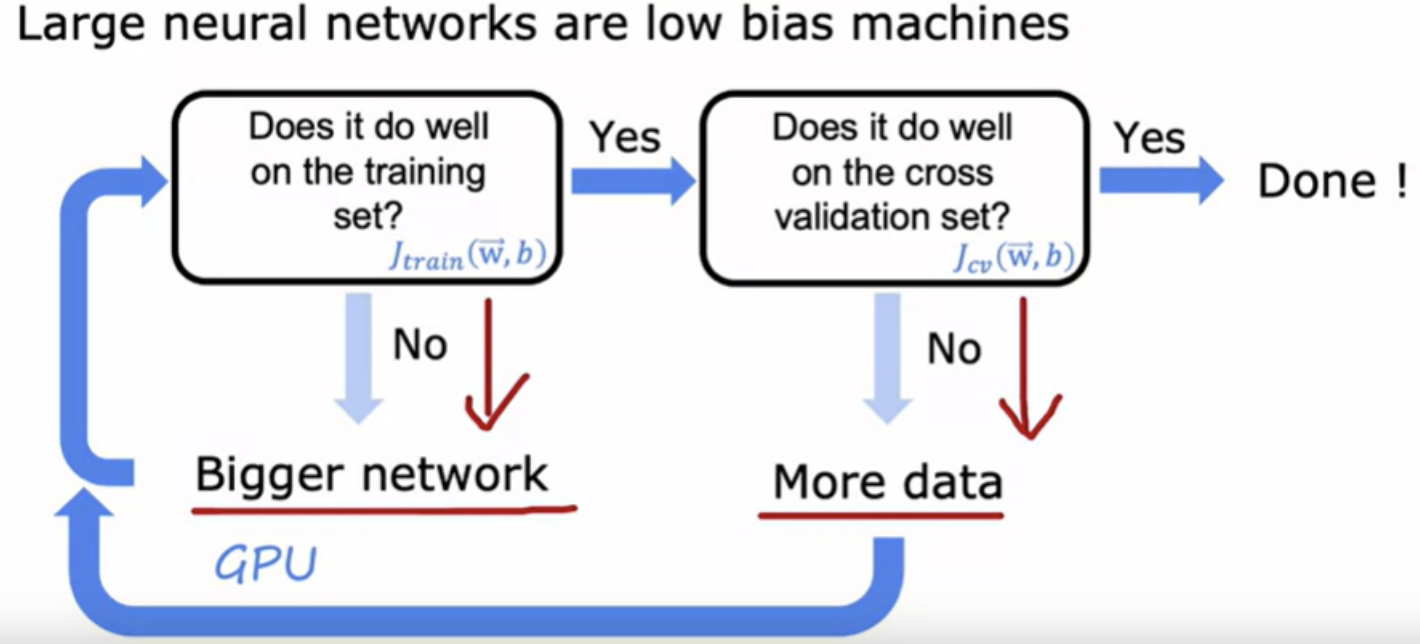
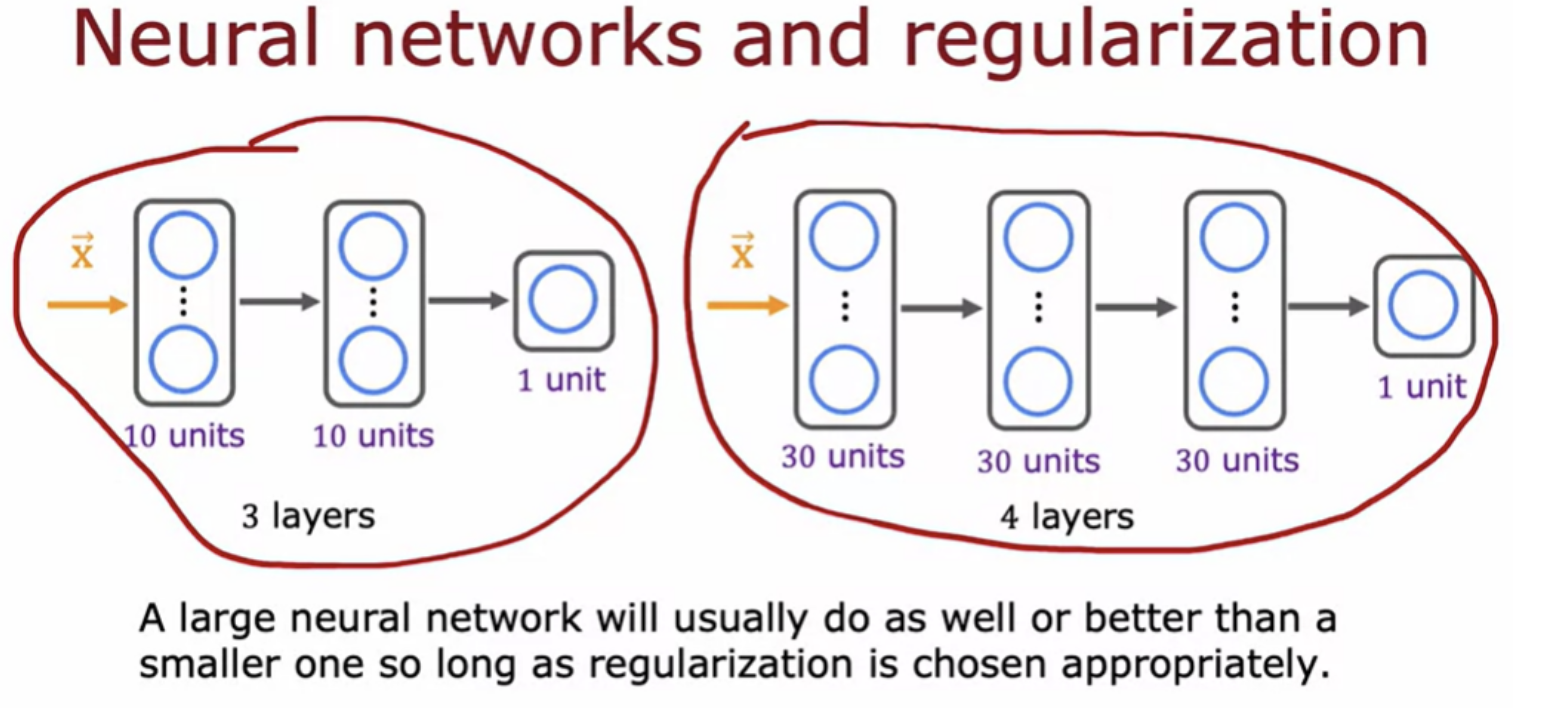
It almost never hurts to go to a larger neural network so long as you regularized appropriately with one caveat, that when you train the larger neural network, it does become more computationally expensive.

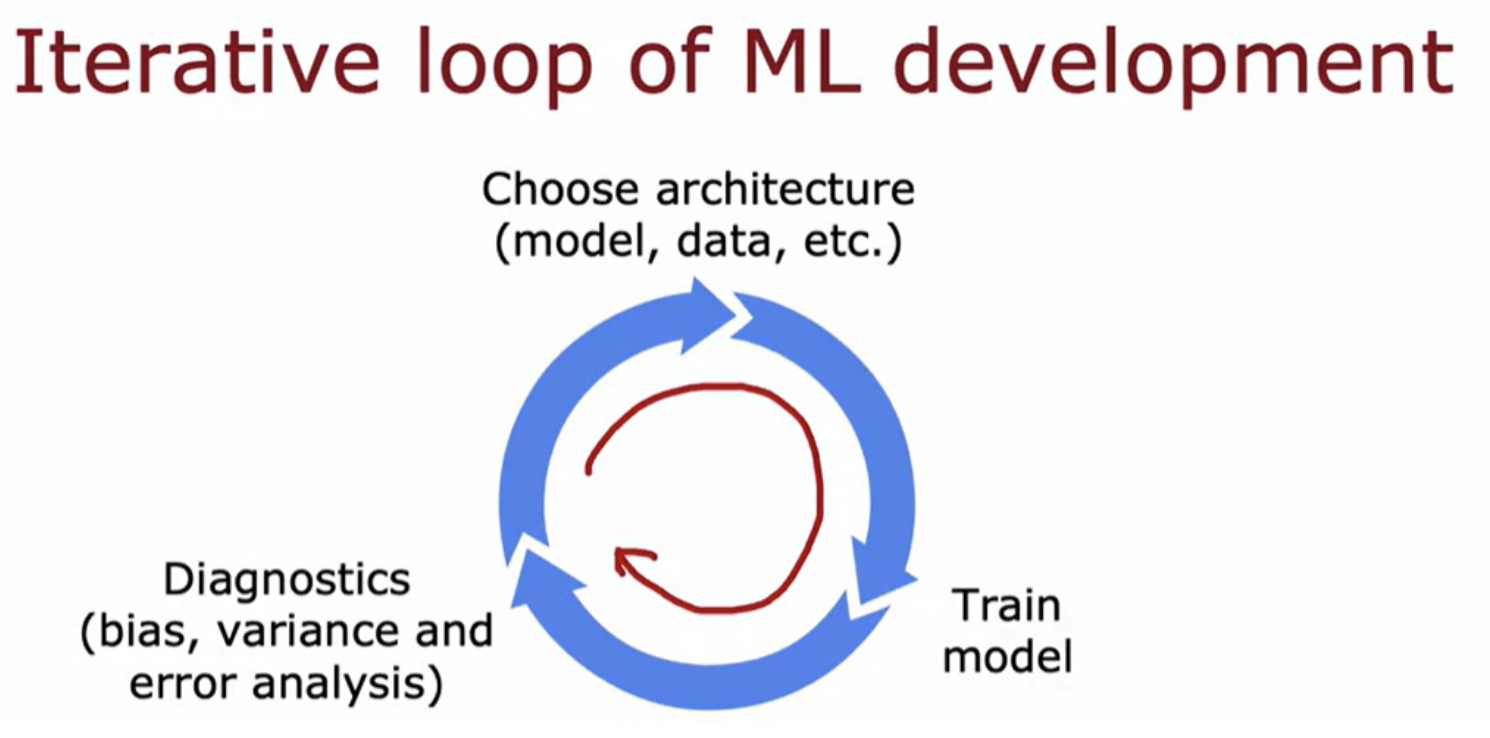
First, you decide on what is the overall architecture of your system. Then, given those decisions, you would implement and train a model. The next step is to implement or to look at a few diagnostics, such as looking at the bias and variance of your algorithm.
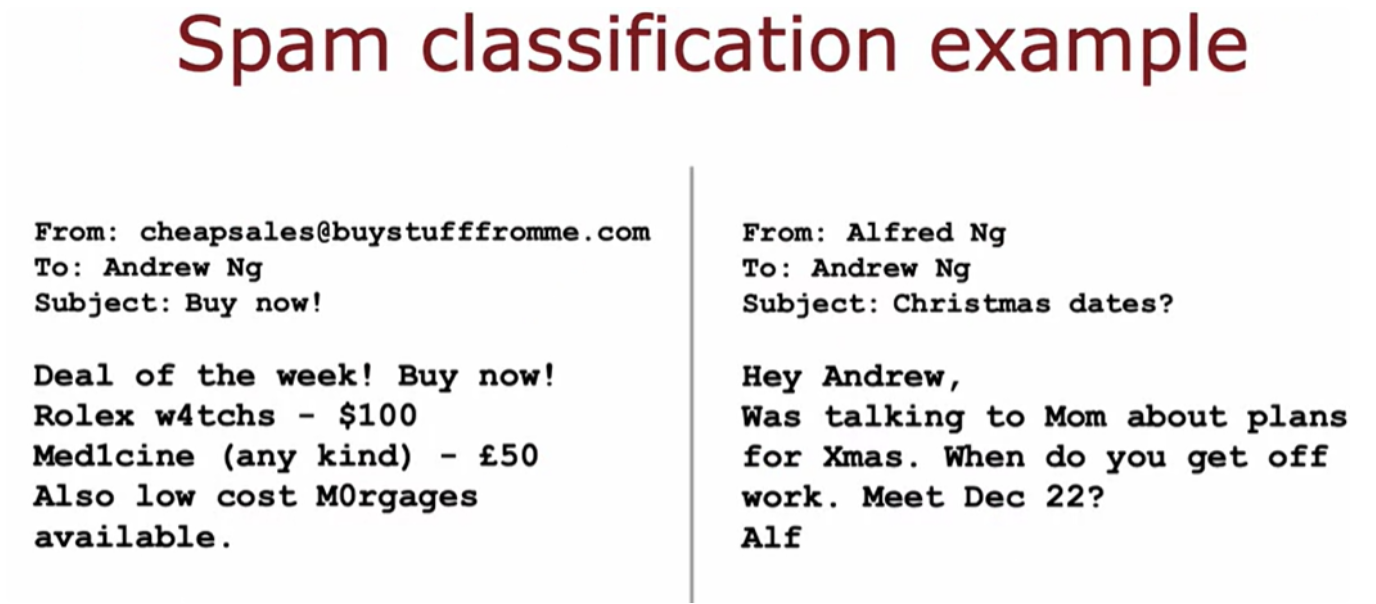

Collect more data for the classifier using a Honeypot project. Then develop sophesticated features based on email routing (from header). Then develop sophesticated features from email body. Also design algoritms to detect mispellings

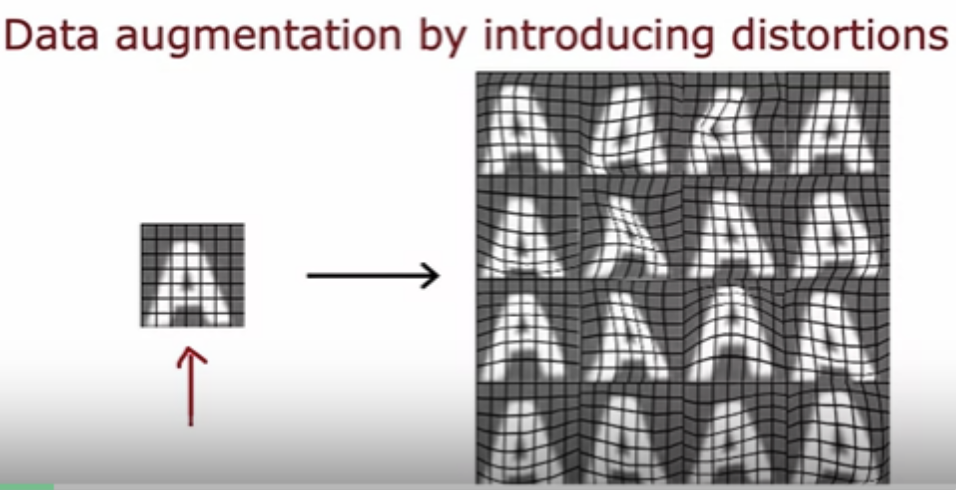
There's another technique that's widely used especially for images and audio data that can increase your training set size significantly, called data augmentation. For example recognize the letters from A to Z for an OCR optical character recognition problem where not just the digits 0-9 but also the letters from A to Z is involved. You might decide to create a new training example by rotating the image a bit. Or by enlarging the image a bit or by shrinking a little bit or by changing the contrast of the image
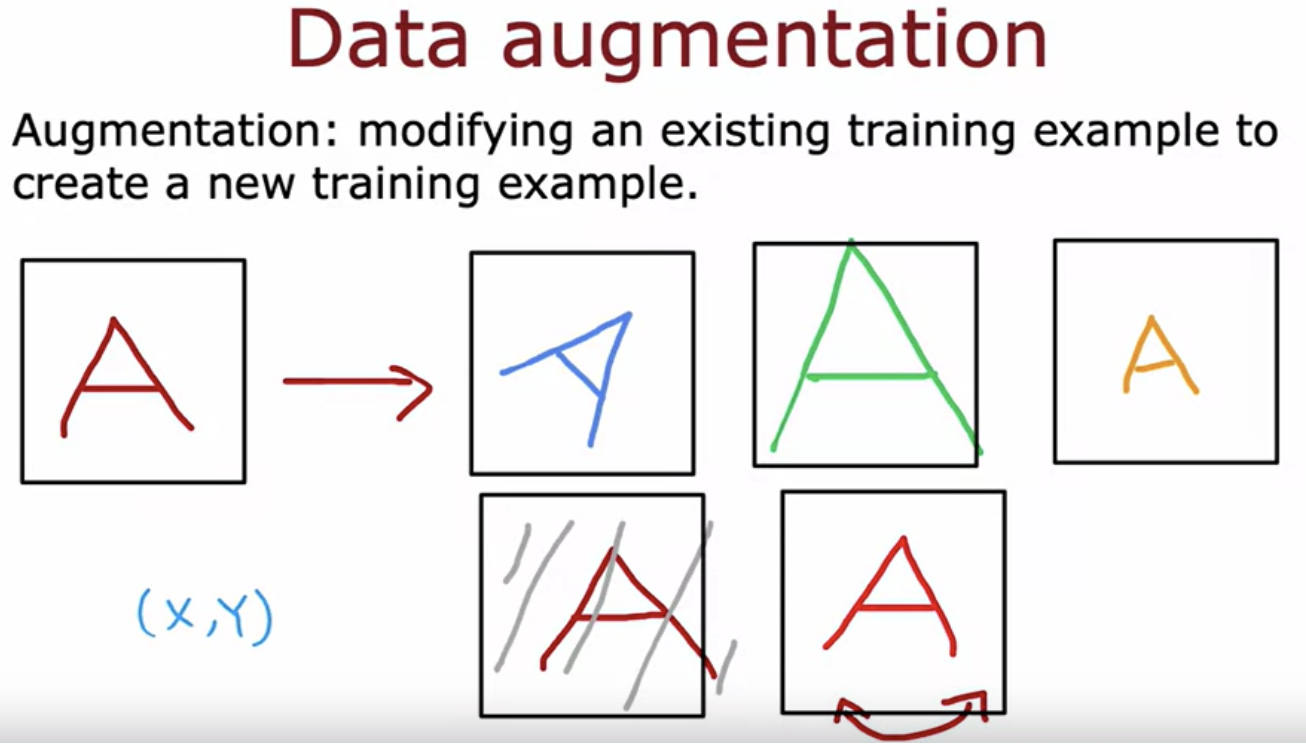
You can also take the letter A and place a grid on top of it. Then introduce random warping of this grid
This idea of data augmentation also works for speech recognition. One way you can apply data augmentation to speech data would be to take noisy background audio, or make the original audio sound like you're recording it on a bad cell phone connection.

sometimes it can be more fruitful to spend more of your time taking a data centric approach in which you focus on engineering the data used by your algorithm
A technique called transfer learning which could give your learning algorithm performance a huge boost. For an application where you don't have that much data, transfer learning is a wonderful technique. It lets you use data from a different task to help on your application.
Let's say you want to recognize the handwritten digits from zero through nine.But you don't have that much labeled data of these handwritten digits. You find a very large datasets of one million images of pictures of cats, dogs, cars, people, and so on, a thousand classes. You can then start by training a neural network on this large dataset of a million images with a thousand different classes and train the algorithm and learn to recognize any of these 1,000 different classes. In this process, you end up learning parameters for the first layer of the neural network w[1], b[1], for the second layer w[2], b[2], w[3], b[3], w[4], b[4] and w[5], b[5] for the output layer.To apply transfer learning, what you do is then make a copy of this neural network where you would keep the parameters w[1], b[1], w[2], b[2], w[3], b[3], w[4], b[4]. But for the last layer you would eliminate the output layer and replace it with a much smaller output layer with just 10 rather than 1,000 output units.These 10 output units will correspond to the classes zero, one, through nine that you want your neural network to recognize. Notice that the parameters w[5], b[5] can't be copied over because the dimension of this layer has changed. So you need to come up with new parameters that you need to train from scratch rather than just copy it from the previous neural network.
One nice thing about transfer learning is that you don't need to be the one to carry out supervised pre-training. For a lot of neural networks, researchers have already trained a neural network on a large image and will have posted a trained neural networks on the Internet freely licensed for anyone to download and use.
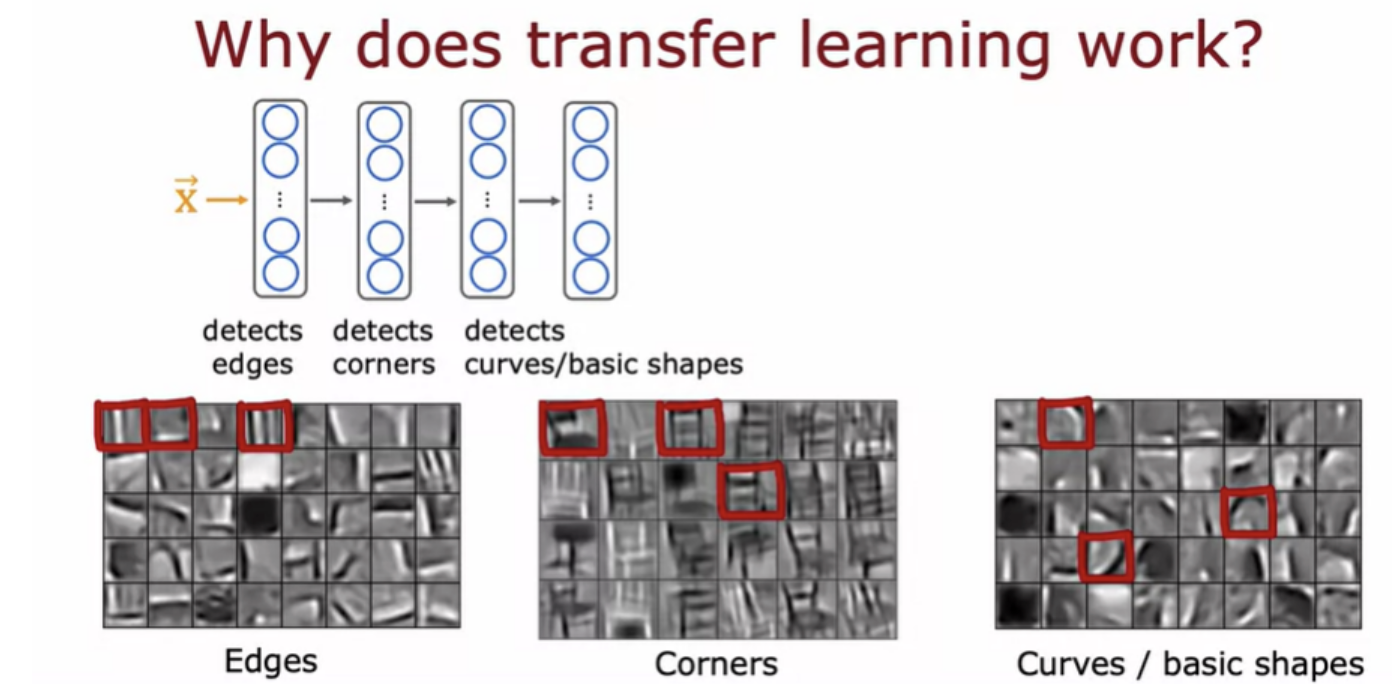
If you are training a neural network to detect, say, different objects from images, then the first layer of a neural network may learn to detect edges in the image.Each of these squares is a visualization of what a single neuron has learned to detect as learn to group pixels together to find edges in an image. The next layer of the neural network then learns to group together edges to detect corners. The next layer of the neural network may have learned to detect some are more complex, but still generic shapes like basic curves or smaller shapes.
If your goal is to build a speech recognition system to process audio, then a neural network pre-trained on images probably won't do much good on audio. Instead, you want a neural network pre-trained on audio data, there you then fine tune on your own audio dataset and the same for other types of applications.

This technique isn't panacea. You can't get every application to work just on 50 images, but it does help a lot when the dataset you have for your application isn't that large
GPT-3 or BERTs are are actually examples of neural networks that they have someone else's pre-trained on a very large image datasets or text dataset. They can then be fine tuned on other applications
If you're working on a machine learning application where the ratio of positive to negative examples is very skewed, very far from 50-50, then it usual error metrics like accuracy don't work that well
Let's say you're training a binary classifier to detect a rare disease in patients based on lab tests. if you have an algorithm that achieve 0.5% error and a different one that achieves 1% error and a different one that achieves 1.2% error, it's difficult to know which of these is the best algorithm.

In this case we usually use a different error metric (precision and recall) rather than just classification error to figure out how well your learning algorithm is doing. Divide the classifications into these four cells.
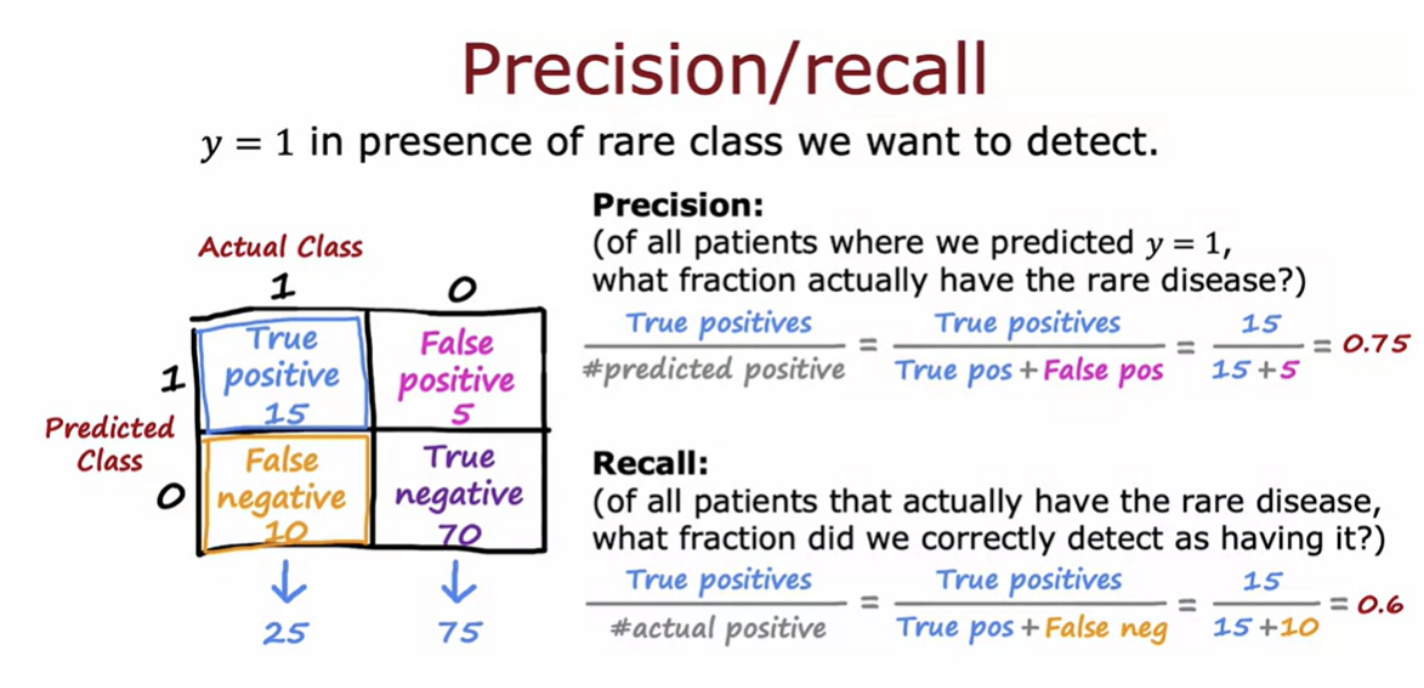
The precision of the learning algorithm computes of all the patients where we predicted y is equal to 1. In other words, precision is defined as the number of true positives divided by the number classified as positive. In other words, of all the examples you predicted as positive, what fraction did we actually get right
Recall is defined as the number of true positives divided by the number of actual positives
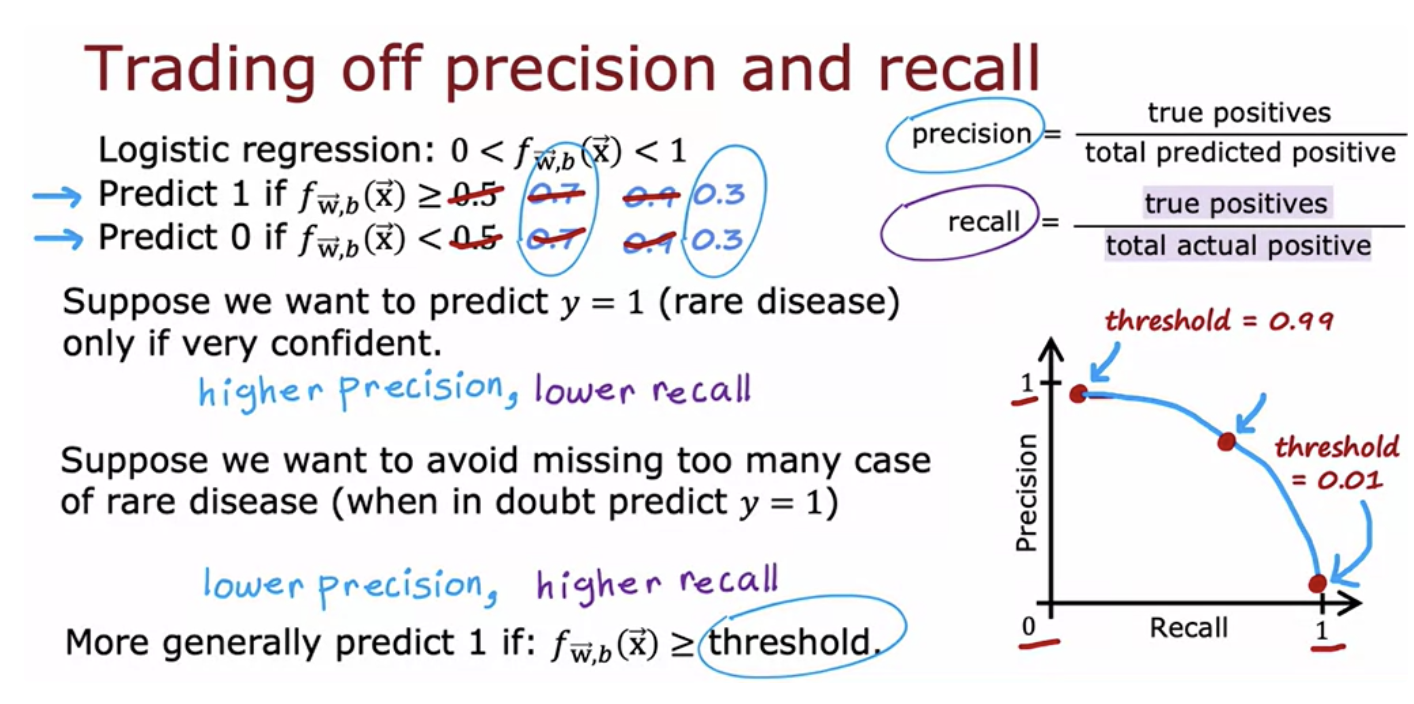
High precision would mean that if a diagnosis of patients have that rare disease, probably the patient does have it and it's an accurate diagnosis. High recall means that if there's a patient with that rare disease, probably the algorithm will correctly identify that they do have that disease. But it turns out that in practice there's often a trade-off between precision and recall
One way you could combine precision and recall is to take the average, which is not a good way.Instead, the most common way of combining precision recall is a compute something called the F1 score.

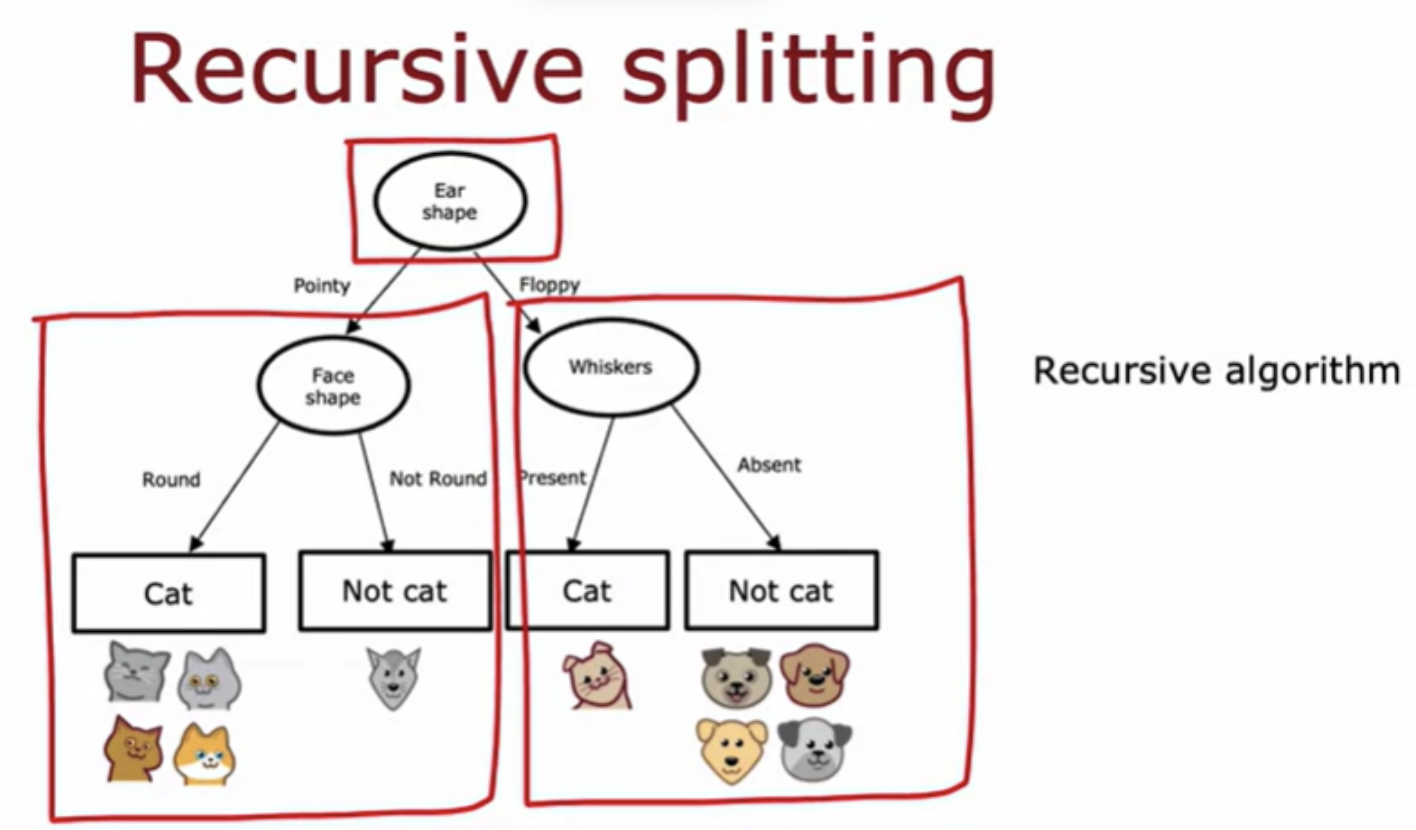
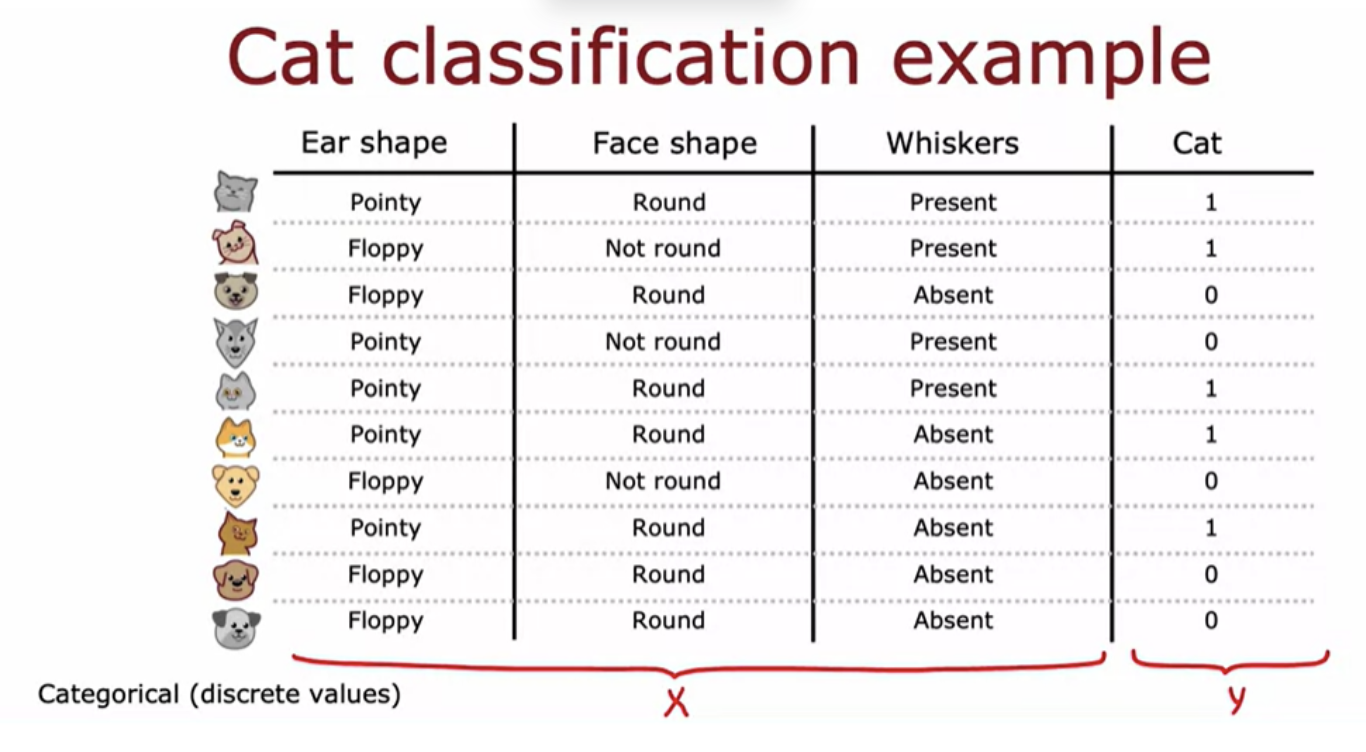
Assume you want to train a classifier to quickly tell you if an animal is a cat or not
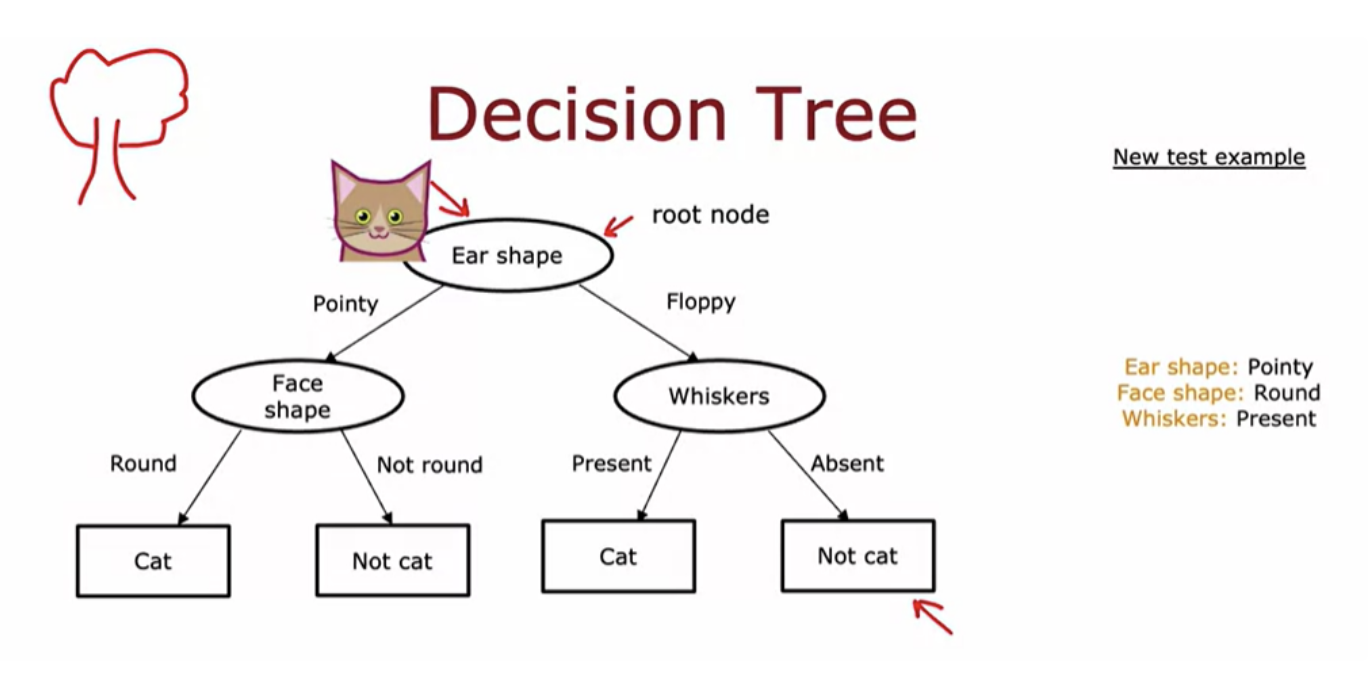
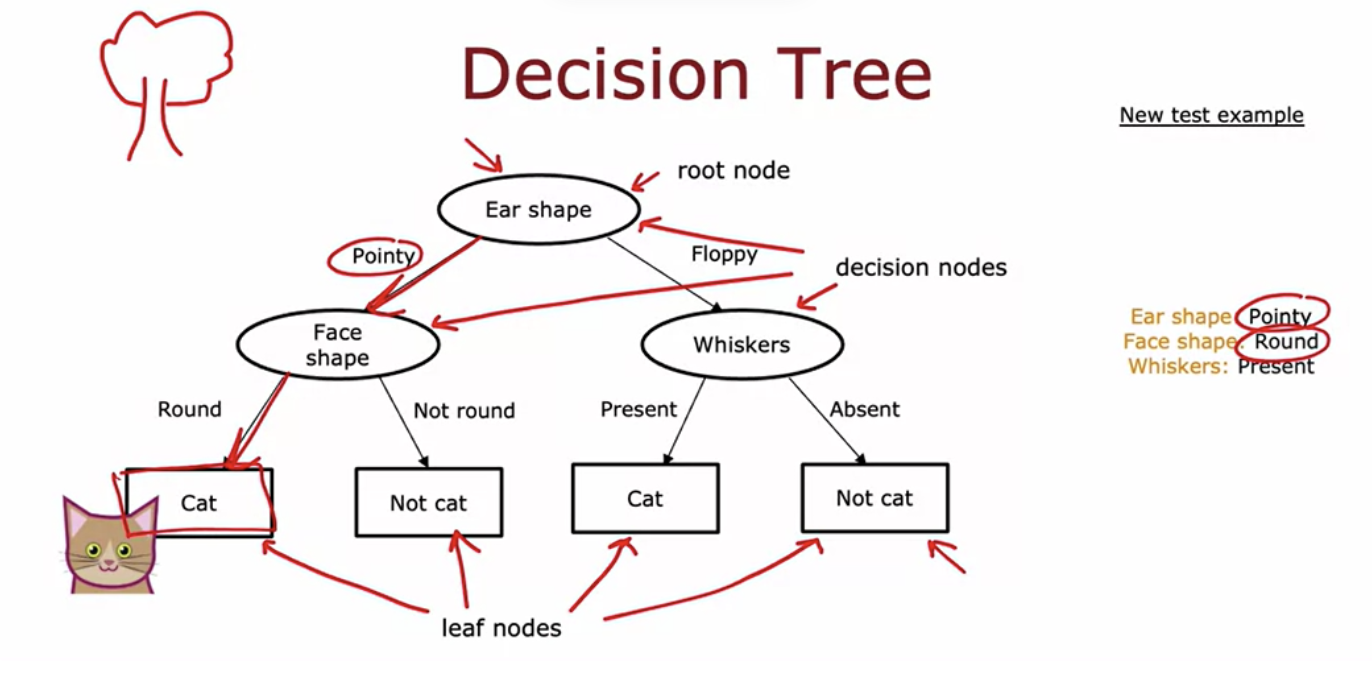
topmost node of the tree is called the root node of the decision tree
The job of the decision tree learning algorithm is, out of all possible decision trees, to try to pick one that hopefully does well on the training set
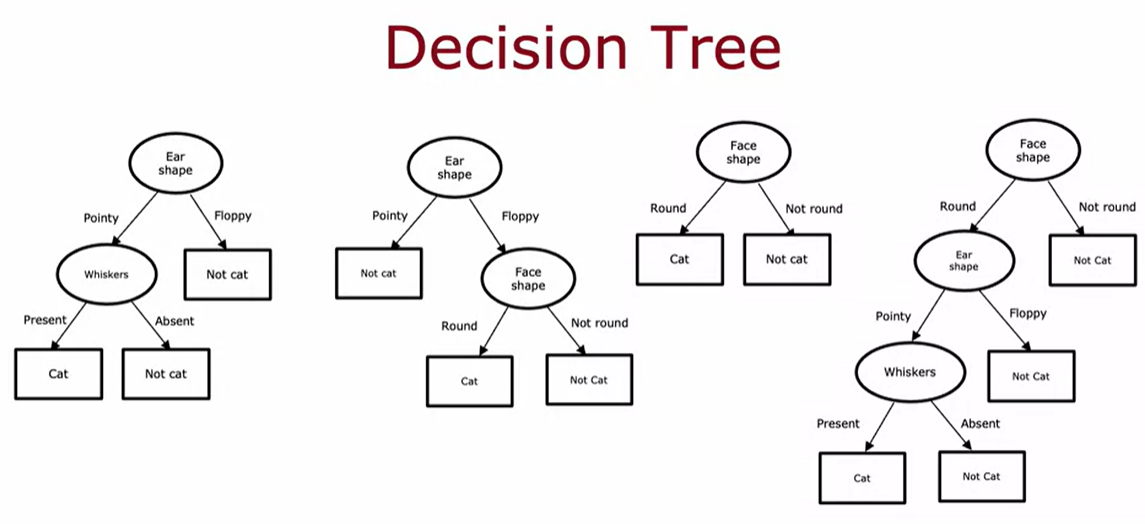
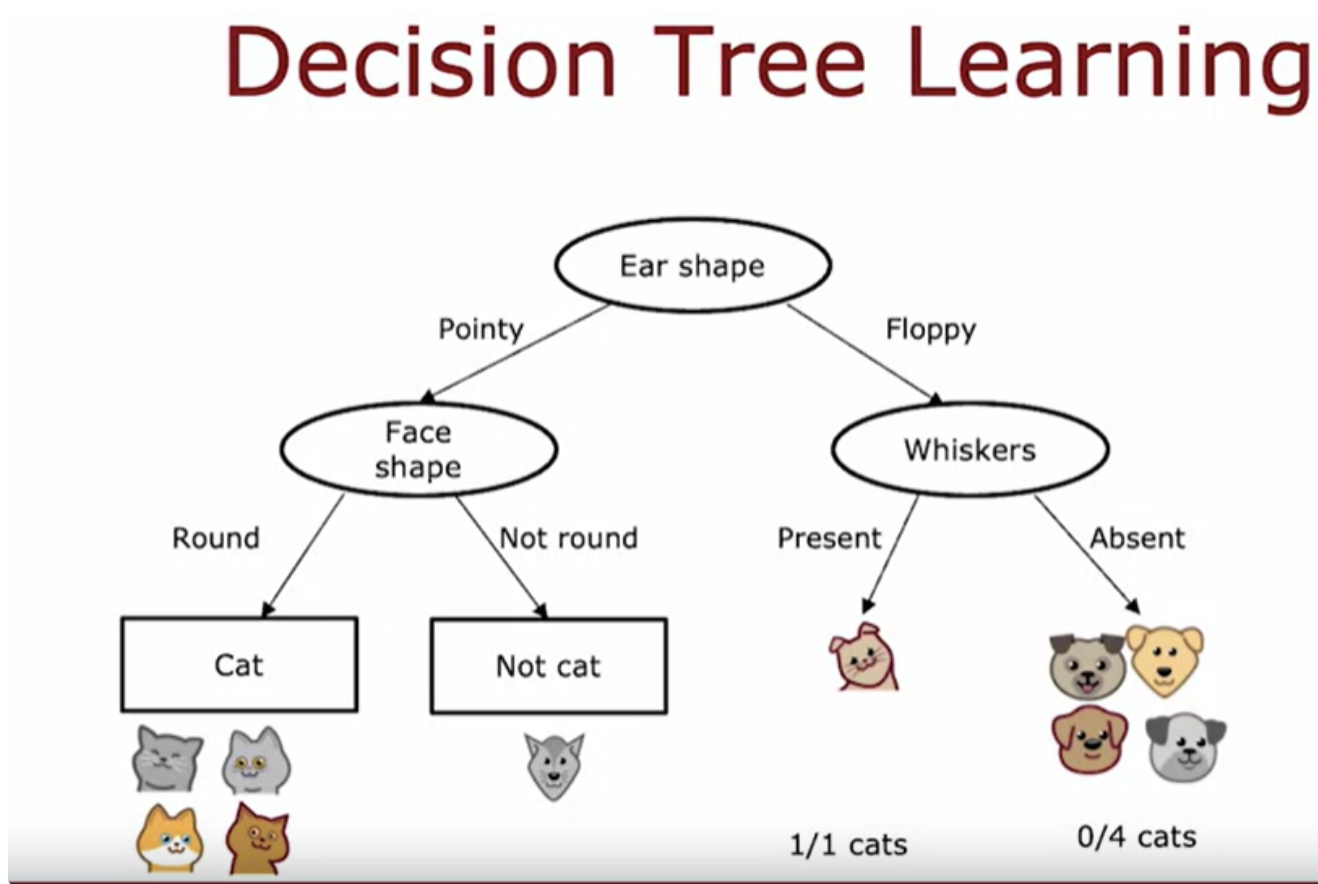
The first key decision was, how do you choose what features to use to split on at each node?. Do you want to split on the ear-shaped feature or the facial feature or the whiskers feature? Which of these features results in the greatest purity of the labels on the left and right sub branches? The second key decision you need to make when building a decision tree is to decide when do you stop splitting.
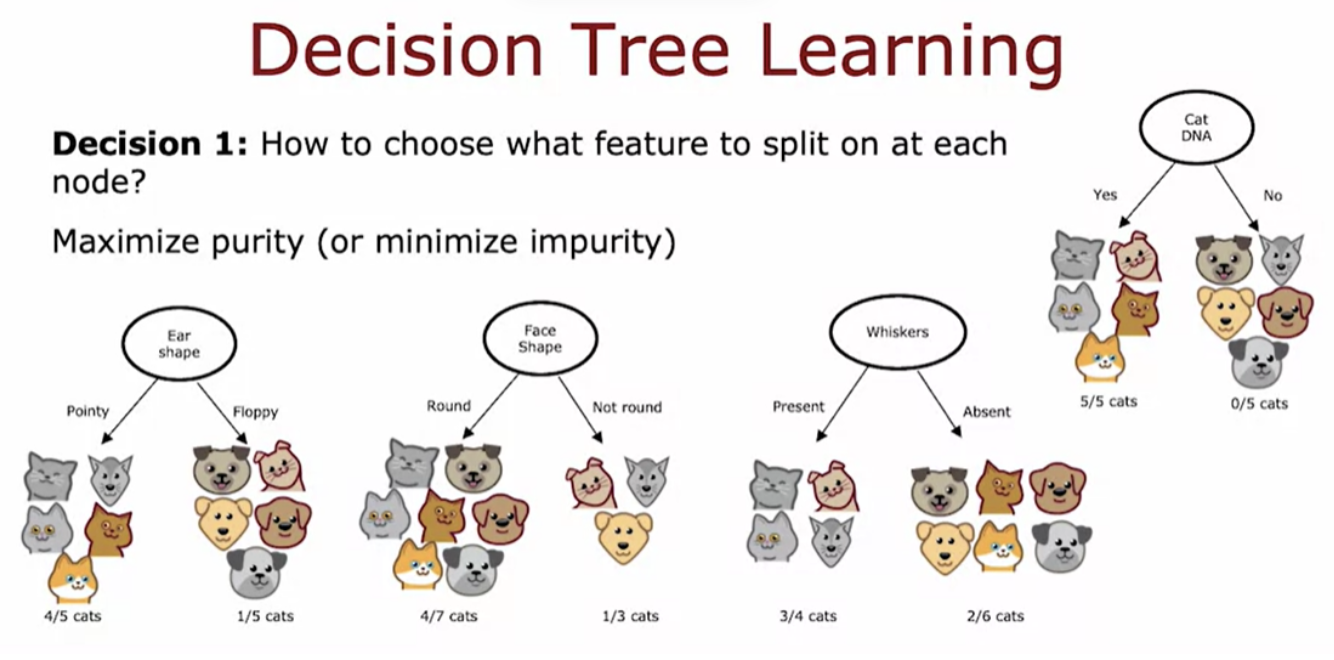

If the examples are all cats of a single class then that's very pure. If it's all not cats that's also very pure, but if it's somewhere in between how do you quantify how pure is the set of examples?

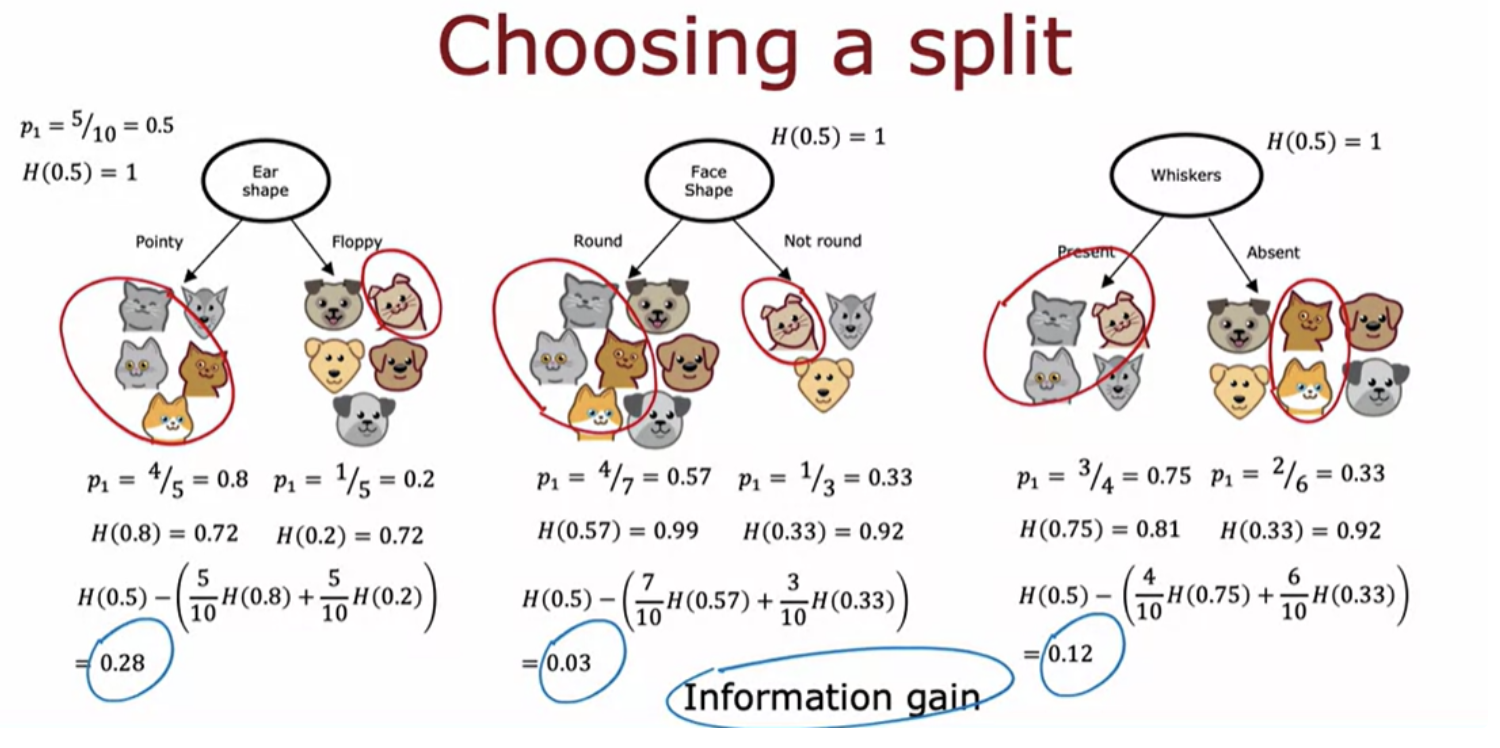

You can calculate the information gain associated with choosing any particular feature to split on in the node.
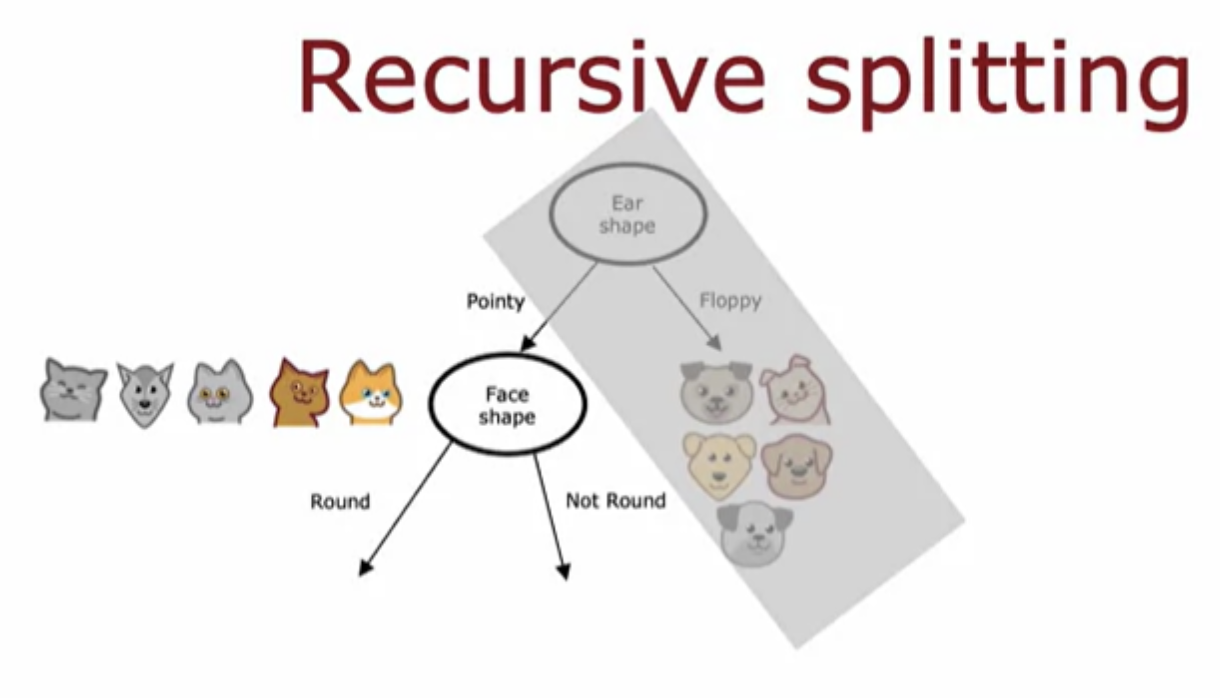
The next step is to then pick a feature to split on. Then go through the features one at a time and compute the information gain of each of those features as if this node were the new root node of a decision tree that was trained using just five training examples shown. In fact, the procedure for building the right sub-branch will be a lot as if you were training a decision tree learning algorithm from scratch, where the dataset you have comprises just these five training examples.