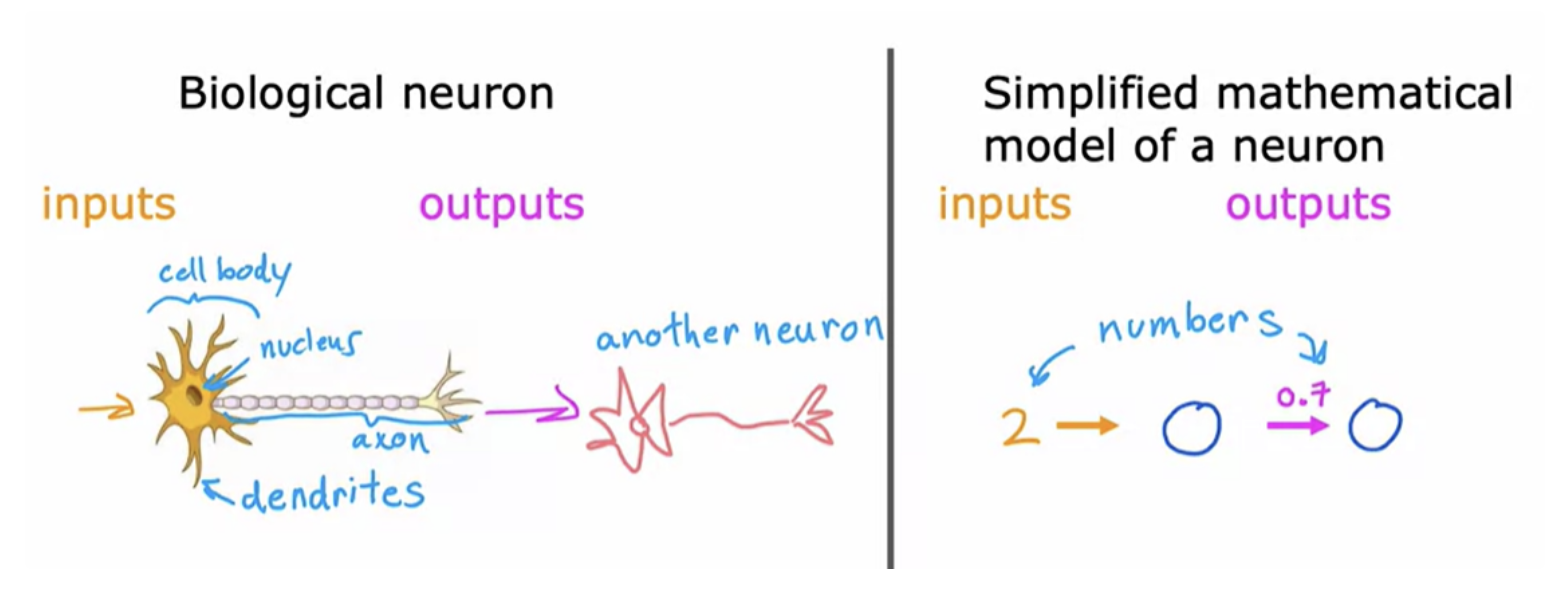
When neural networks were first invented many decades ago, the original motivation was to write software that could mimic how the human brain or how the biological brain learns and thinks. Work in neural networks had started back in the 1950s.
When you're building an artificial neural network or deep learning algorithm, rather than building one neuron at a time, you often simulate many such neurons at the same time
Those of us that do research in deep learning have shifted away from looking to biological motivation that much. But instead, they're just using engineering principles to figure out how to build algorithms that are more effective.
Let us use an example from demand prediction
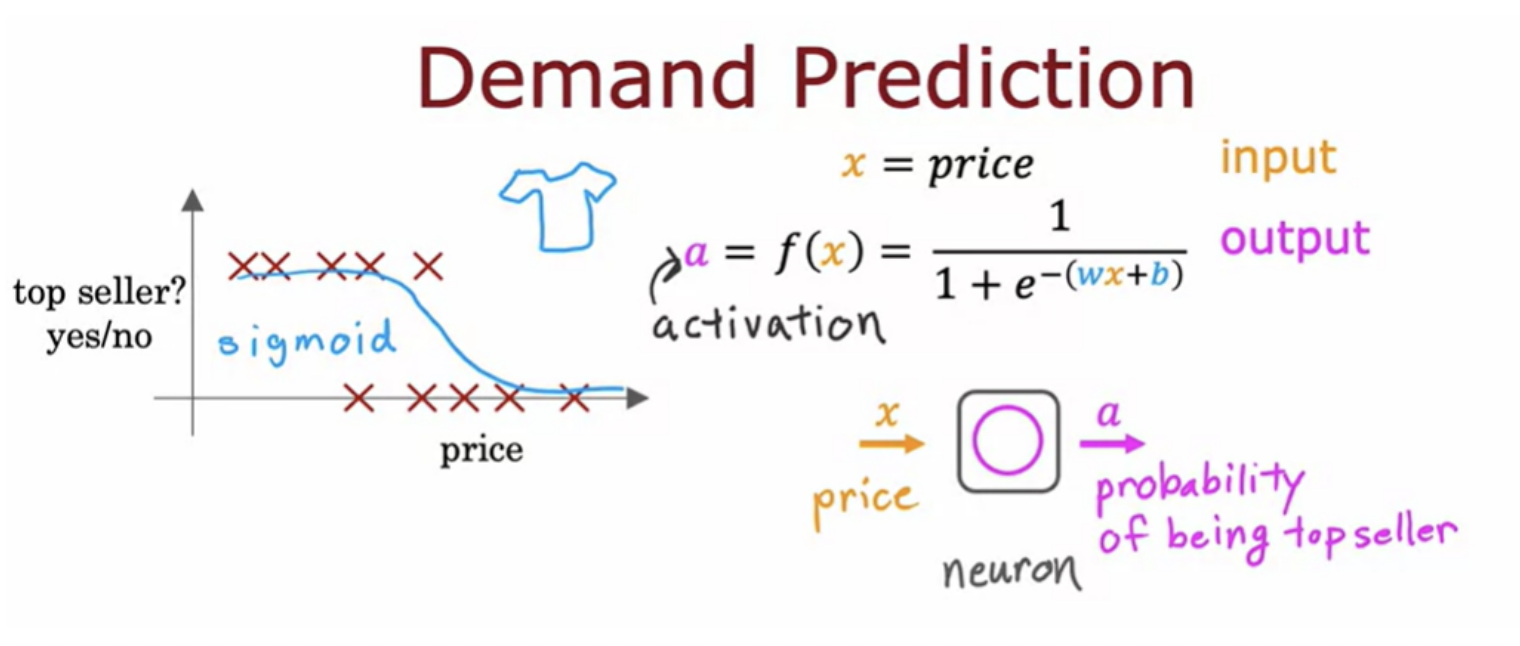
Let us use the alphabet “a” to denote the output of this logistic regression algorithm. The term a stands for activation, and it's a term from neuroscience. It refers to how much a neuron is sending a high output to other neurons downstream from it.
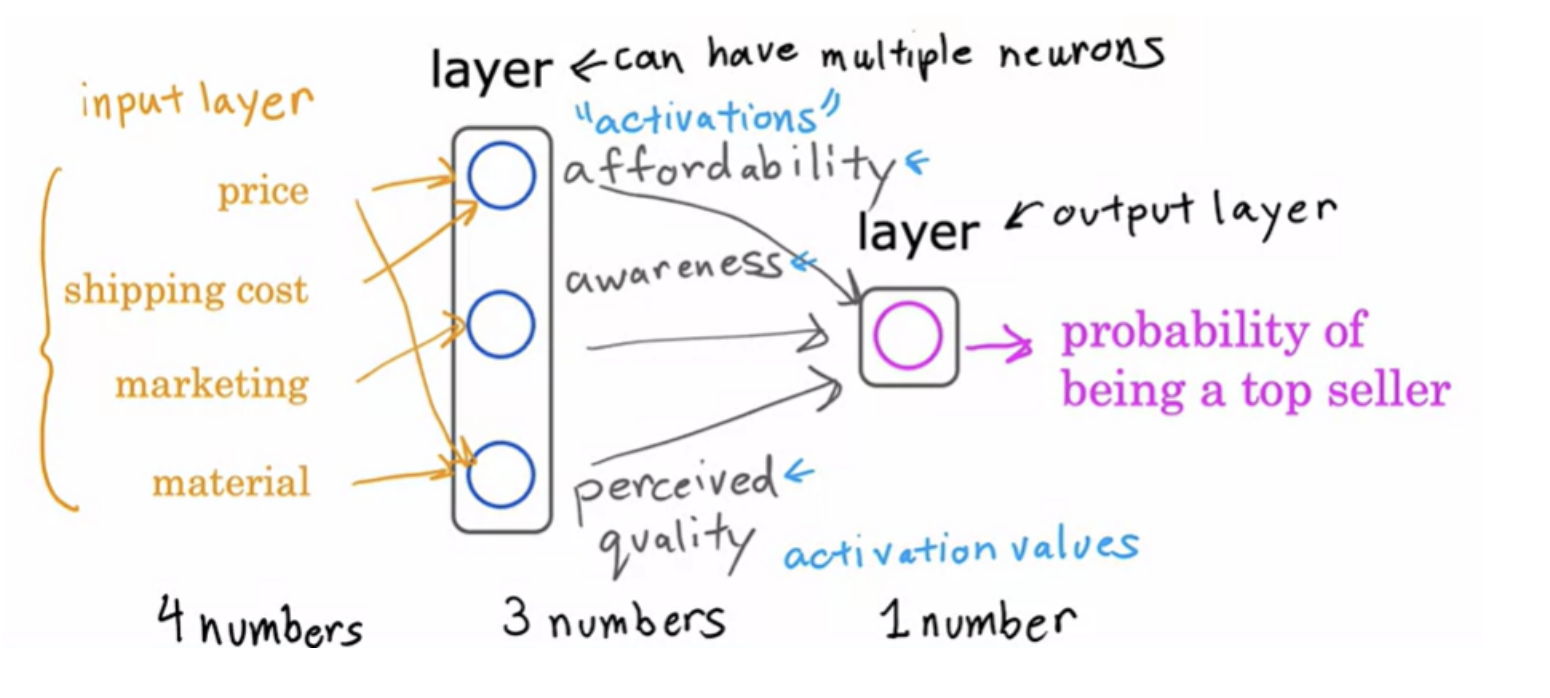
This unit of logistic regression algorithm, can be thought of as a very simplified model of a single neuron in the brain. Building a neural network now it just requires taking a bunch of these neurons and wiring them together or putting them together. A layer is a grouping of neurons which takes as input the same or similar features, and that in turn outputs a few numbers together.
Hidden Layer
Your data set tells you what is x and what is y. ie, you have information on the correct inputs and the correct outputs. But your dataset doesn't tell you what are the correct values for affordability, awareness, and perceived quality. The correct values for those are hidden. You don't see them in the training set, which is why this layer in the middle is called a hidden layer.
The input layer has a vector of features (four numbers in this example) it is input to the hidden layer, which outputs three numbers.
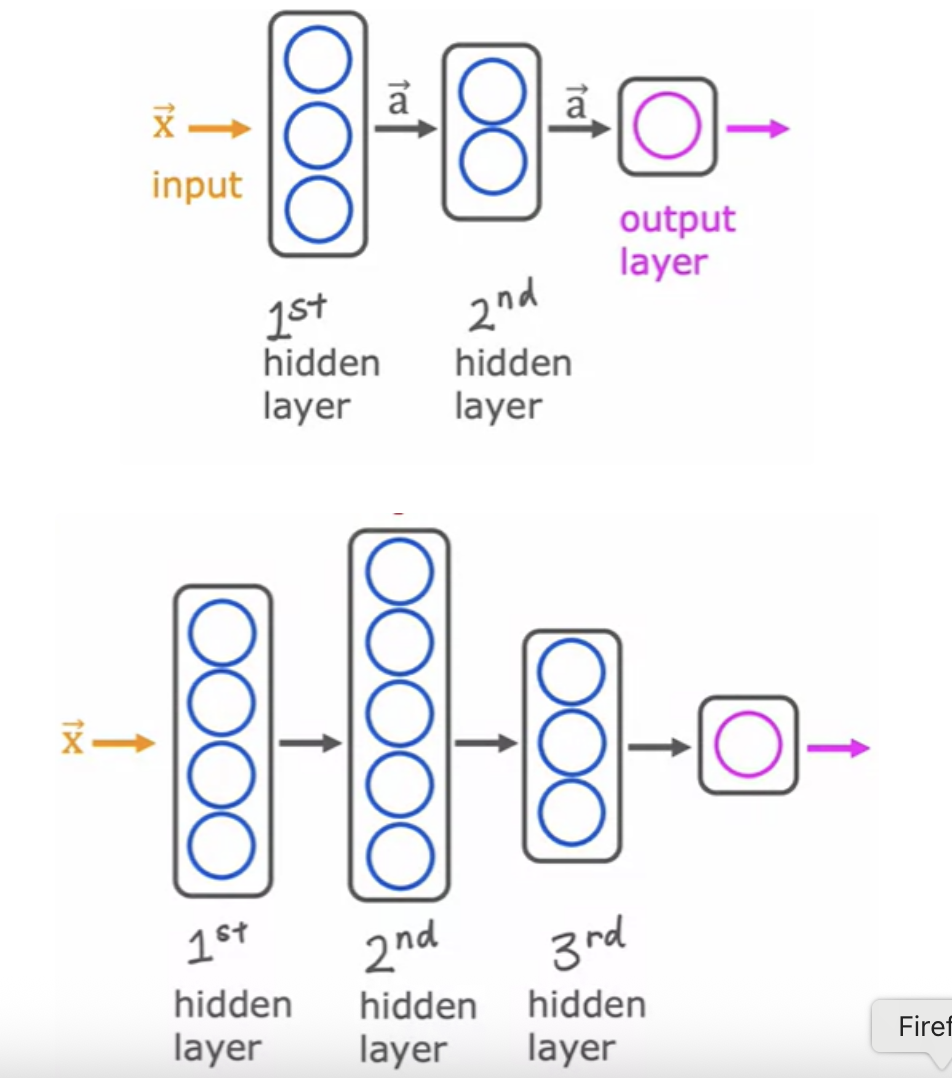
When you're building your own neural network, one of the decisions you need to make is how many hidden layers do you want and how many neurons do you want each hidden layer to have. It is a question of the architecture of the neural network. But choosing the right number of hidden layers and number of hidden units per layer can have an impact on the performance of a learning algorithm as well.
The term multilayer perceptron just refers to a neural network that looks like the above.
For building a face recognition application, you will train a neural network that takes as input a picture and outputs the identity of the person in the picture. This image example is 1,000 by 1,000 pixels. It is a 1000 by 1000 matrix of pixel intensity values.
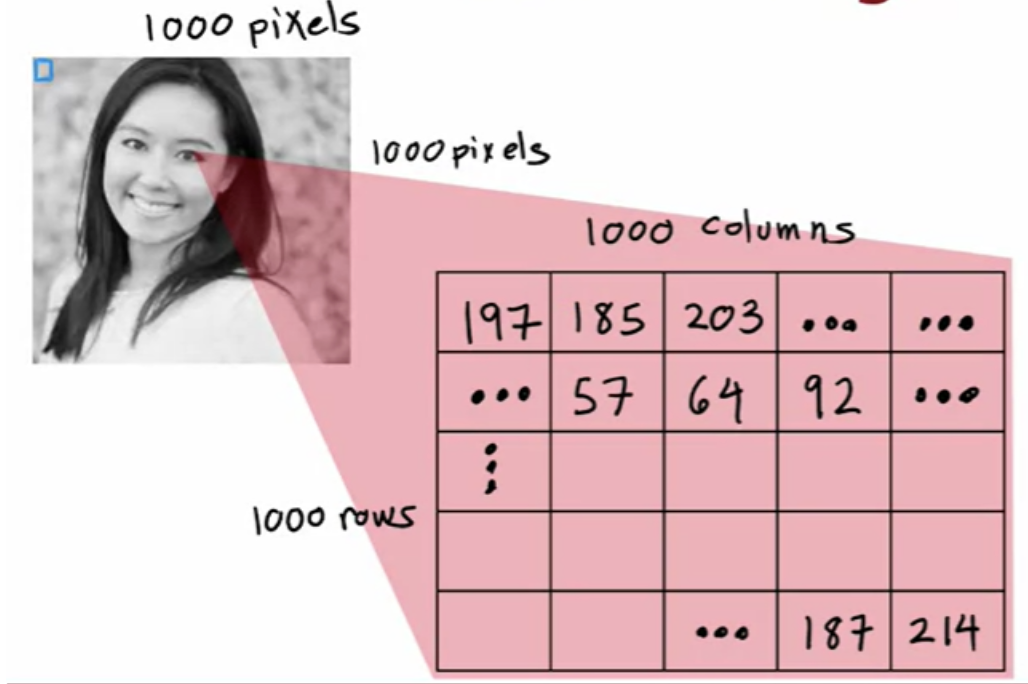
If you were to take these pixel intensity values and unroll them into a vector, you end up with a list or a vector of a million (1000x1000) pixel intensity values. The face recognition problem is thus about training a neural network that takes as input a feature vector with a million pixel values and outputs the identity of the person in the picture
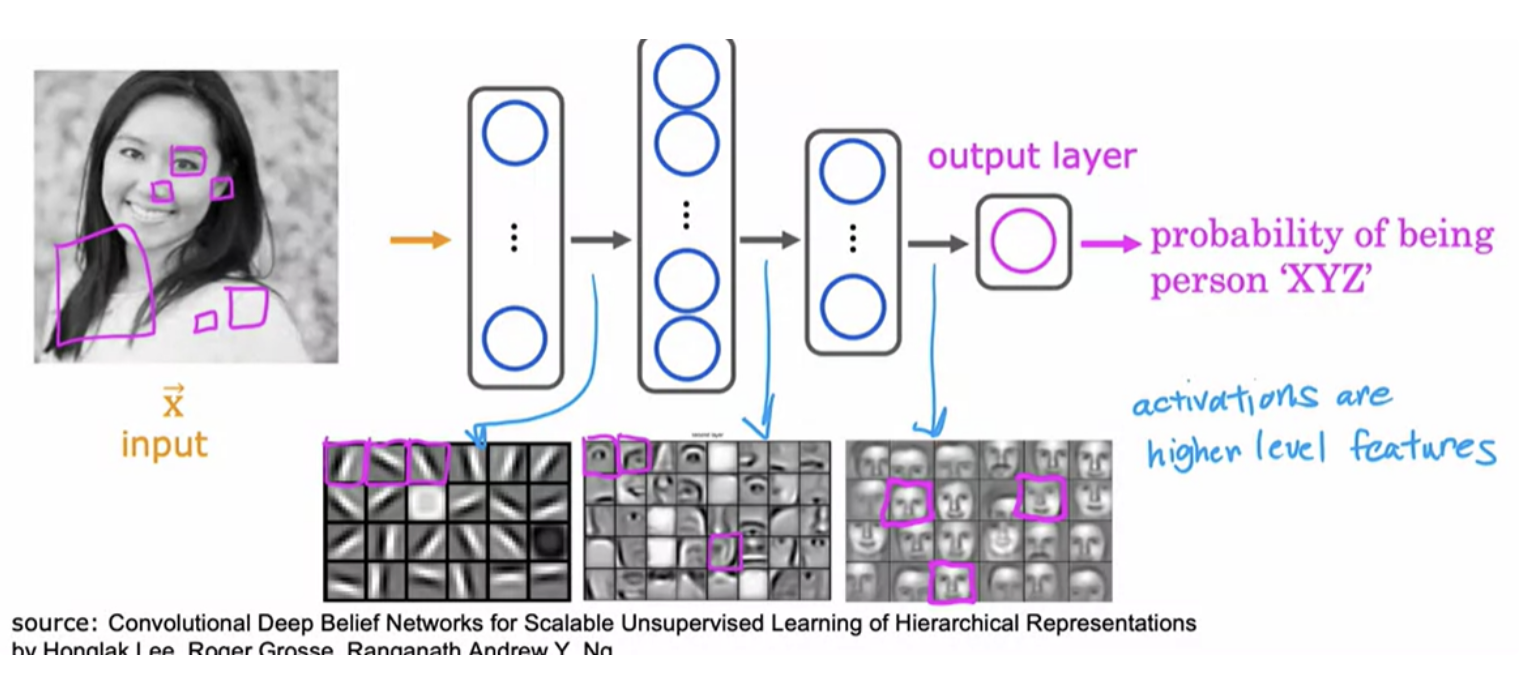
In the first hidden layer, you might find one neuron that is looking for the low vertical line or a vertical edge . A second neuron looking for a oriented line or oriented edge . The third neuron looking for a line at that orientation, and so on. The neural network is aggregating different parts of faces to then try to detect presence or absence of larger, coarser face shapes
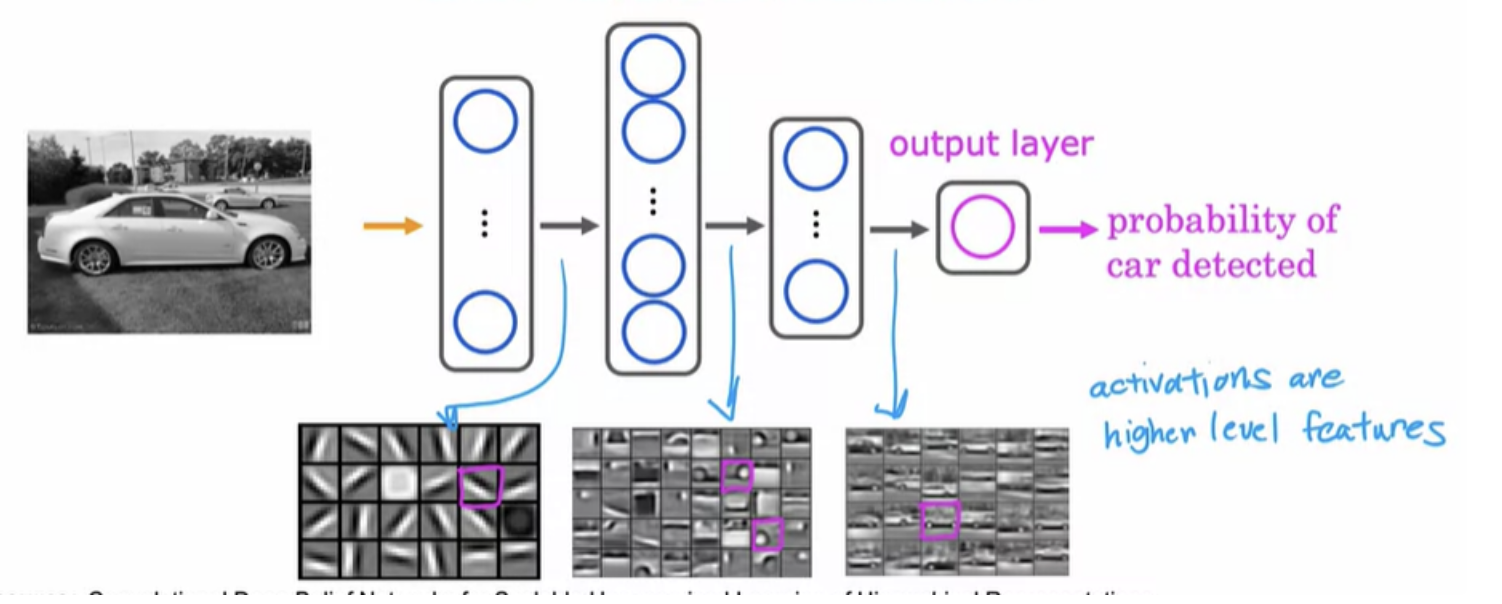
The same learning algorithm is asked to detect cars, will then learn edges in the first layer. Pretty similar but then they'll learn to detect parts of cars in the second hidden layer and then more complete car shapes in the third hidden layer. Just by feeding it different data, the neural network automatically learns to detect very different features so as to try to make the predictions of car detection or person recognition.
The fundamental building block of most modern neural networks is a layer of neurons. Take an example of four input features that were set to layer of three neurons in the hidden layer that then sends its output to output layer with just one neuron
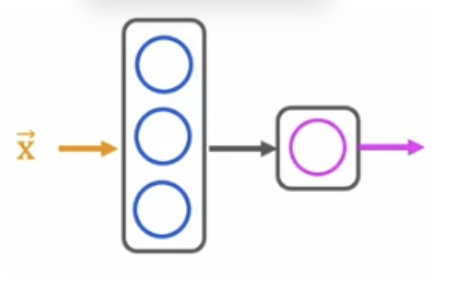
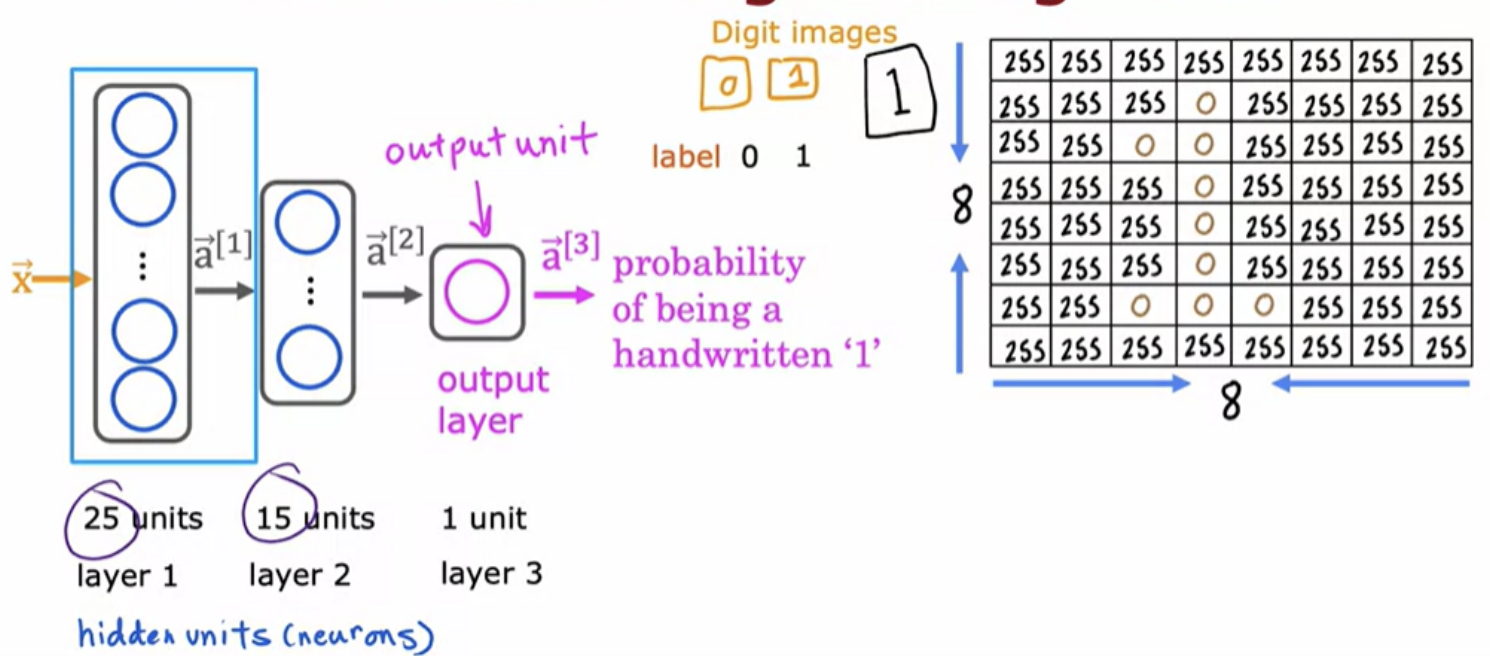
This hidden layer inputs four numbers and these four numbers are inputs to each of three neurons. Each of these three neurons is just implementing a little logistic regression function. Zooming in:
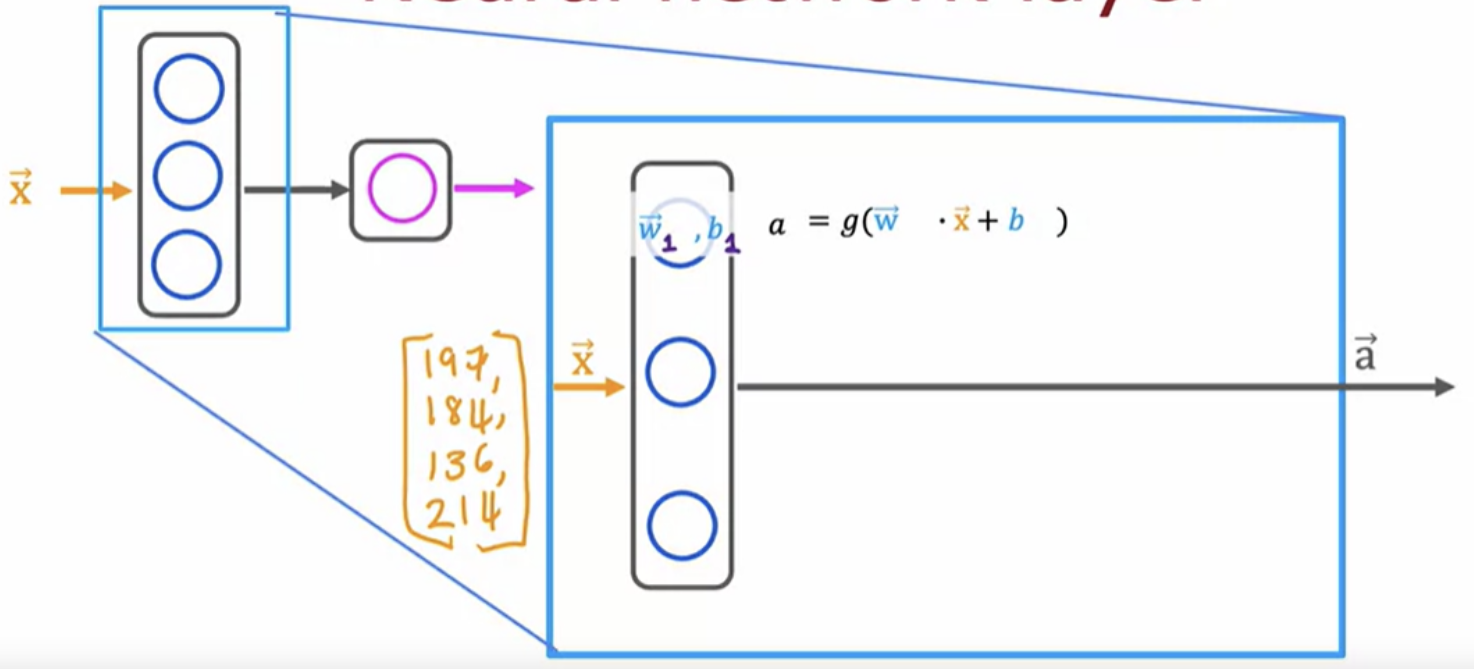
Take the first neuron. It has two parameters, w and b. In this example, these three neurons output 0.3, 0.7, and 0.2, and this vector of three numbers becomes the vector of activation values "a".
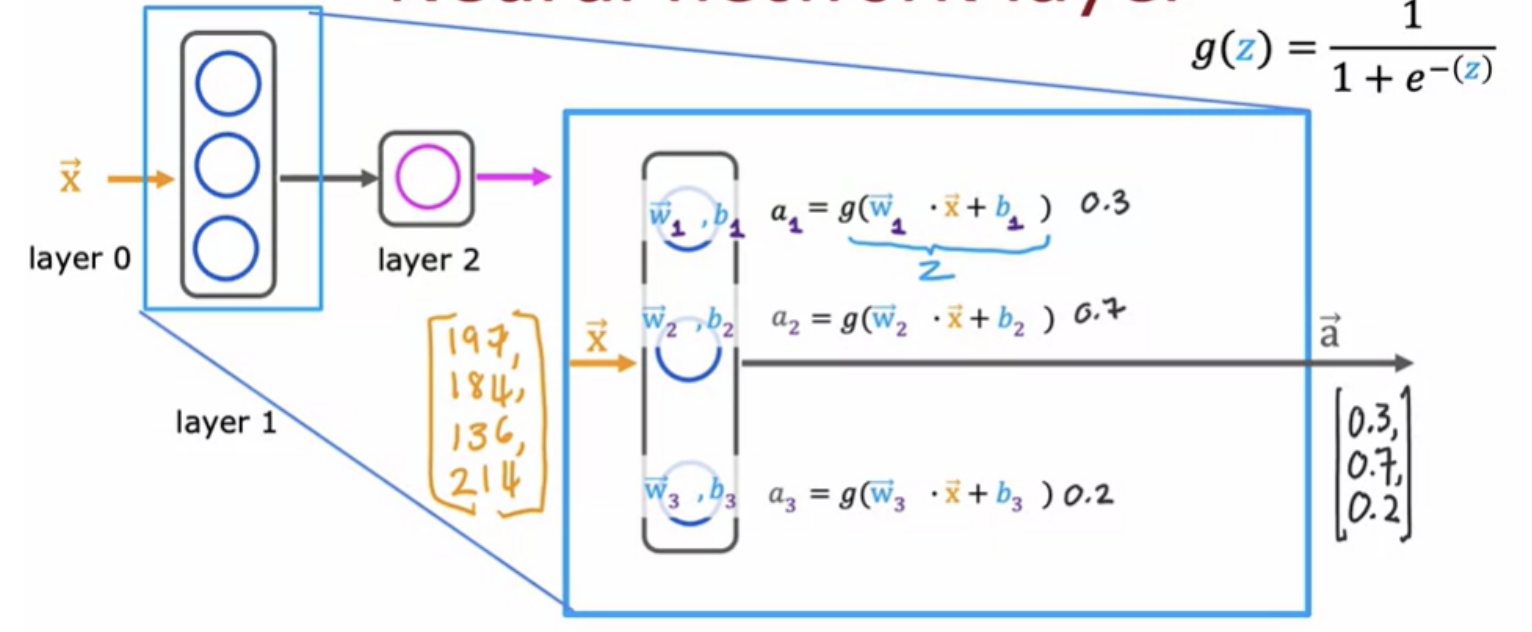
The input layer is also sometimes called layer 0. There are neural networks that can have dozens or even hundreds of layers.
There's a final optional step that you can choose to implement or not, - if you want a binary prediction "is this a top seller? Yes or no?""
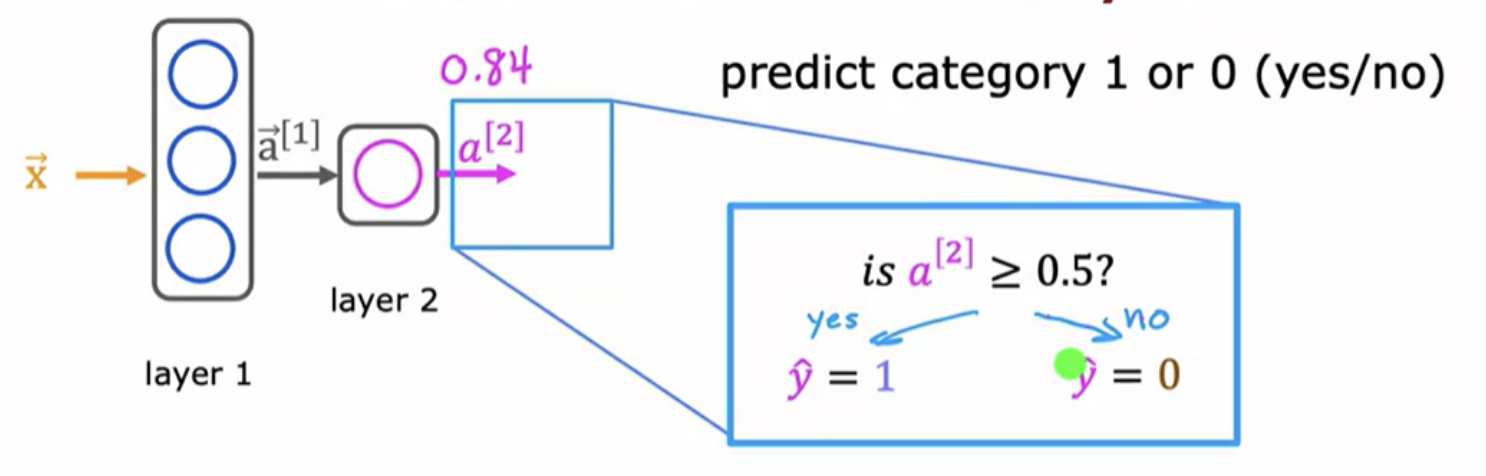
Every layer inputs a vector of numbers and applies a bunch of logistic regression units to it. Then computes another vector of numbers that then gets passed from layer to layer, until you get to the final output layers computation, which is the prediction of the neural network. Then you can either threshold at 0.5 or not to come up with the final prediction.
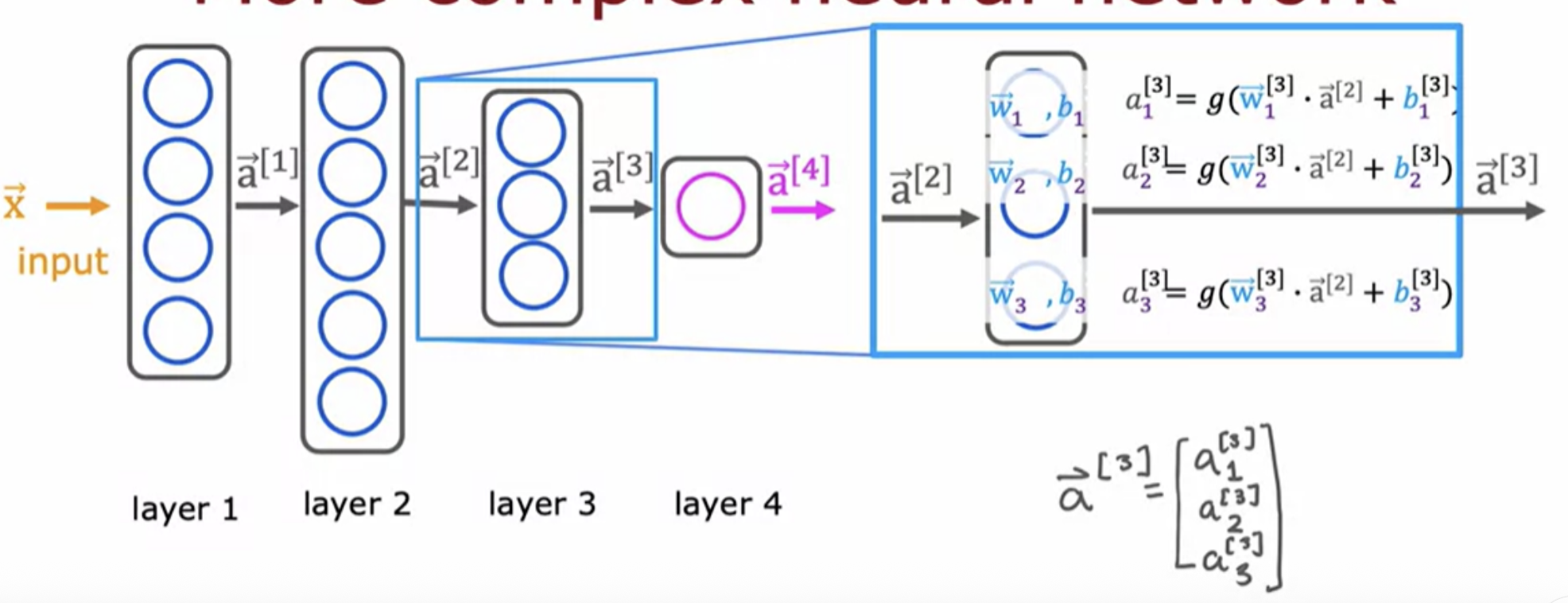
Layer 0 is the input layer. Layer 1, 2, 3 are hidden layers. Layer 4 is the output layer:
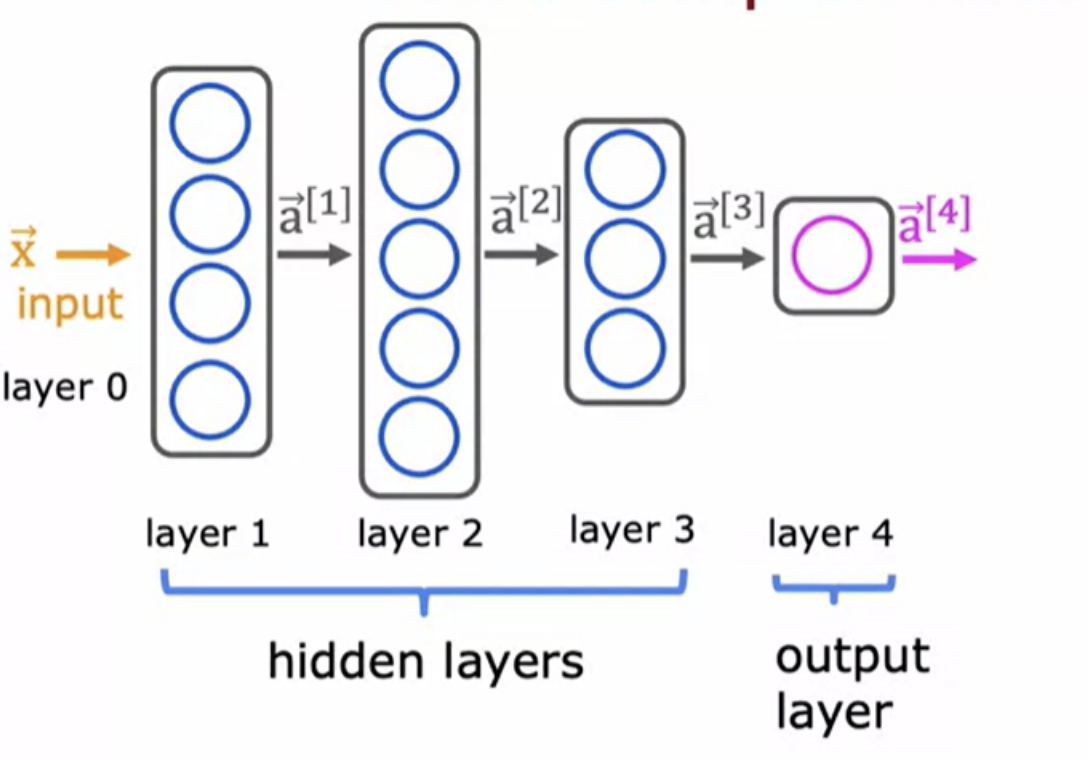
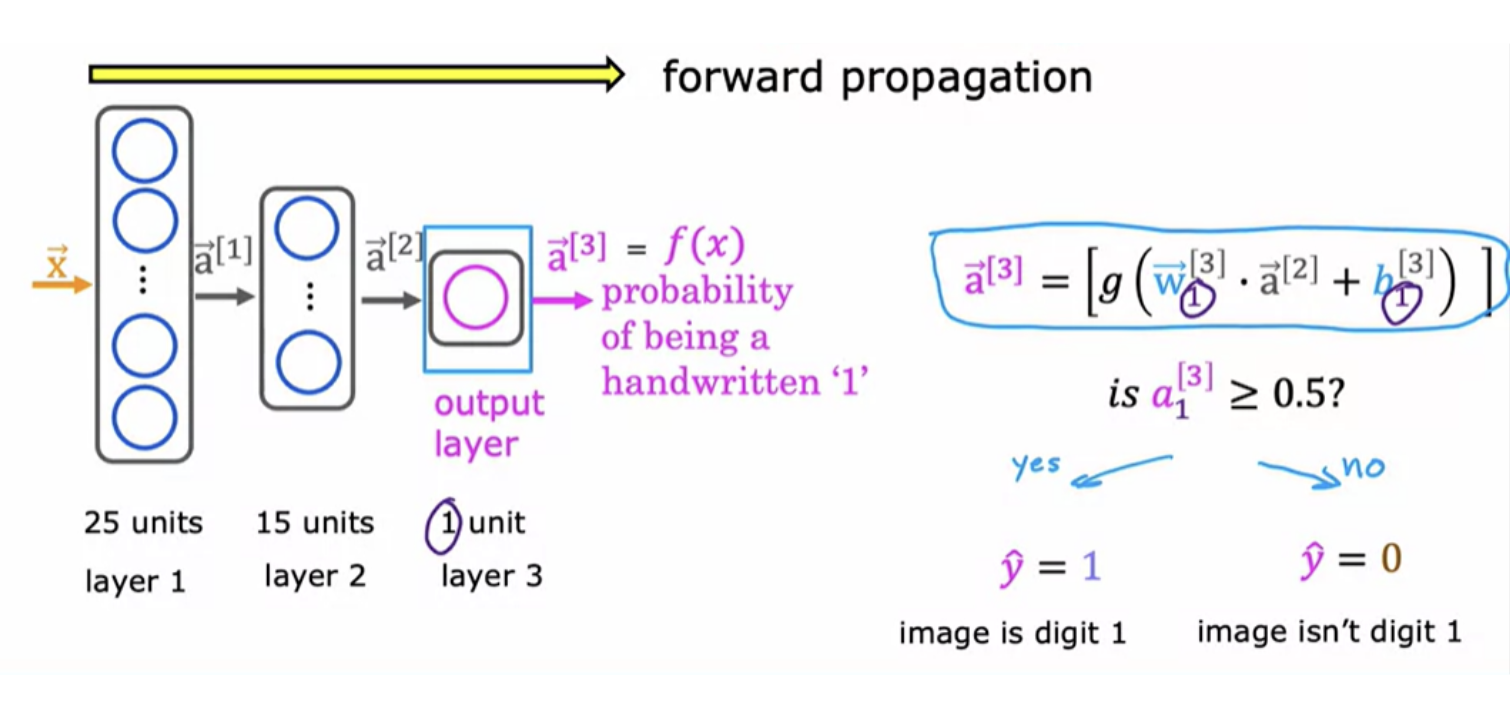
Handwritten digit recognition:
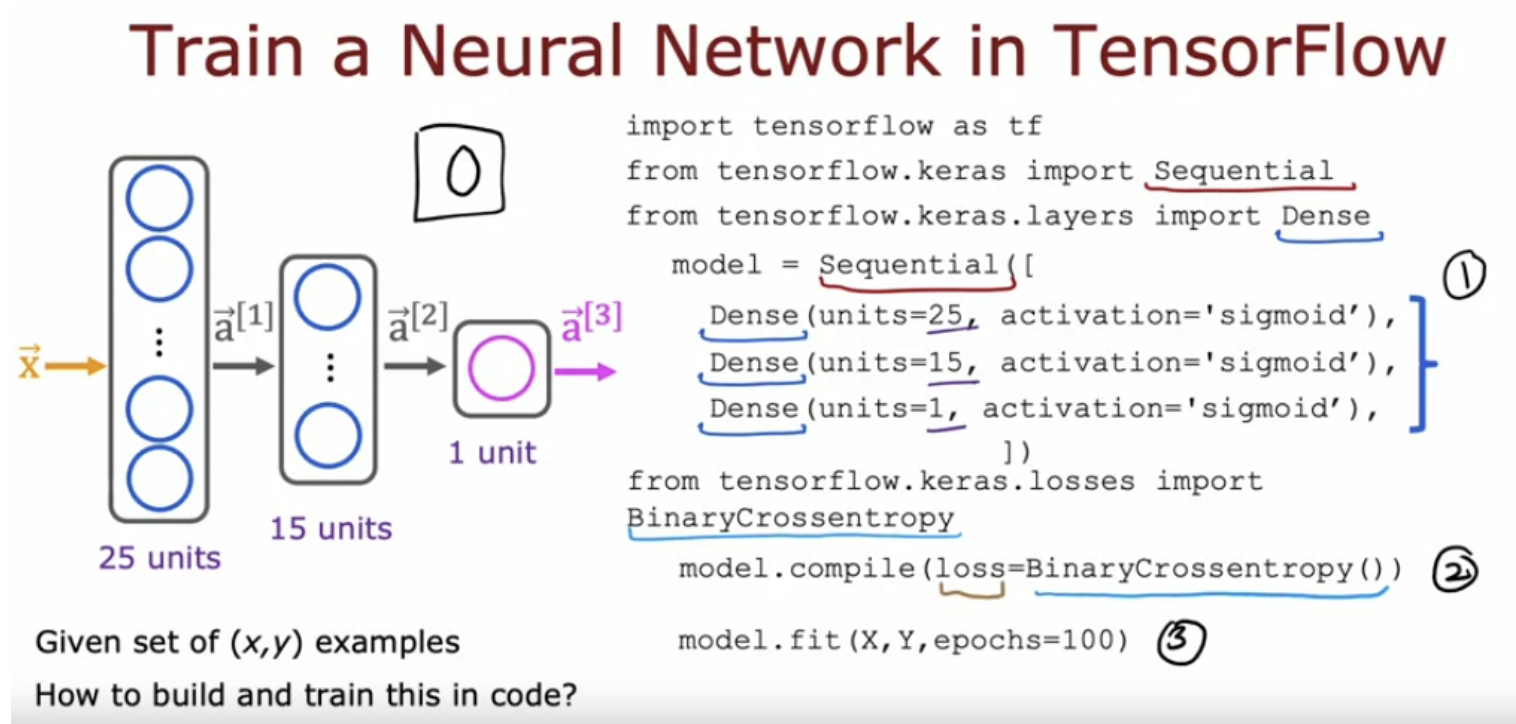
We have an image of a "one" in a grid/matrix of 8x8 = (64) pixel intensity values where 255 denotes a bright white pixel and zero would denote a black pixel. Different numbers are different shades of gray in between the shades of black and white. Given these 64 input features, we're going to use the neural network with two hidden layers. First hidden layer has 25 neurons or 25 units. Second hidden layer has 15 neurons or 15 units. And then finally the output layer.
where:
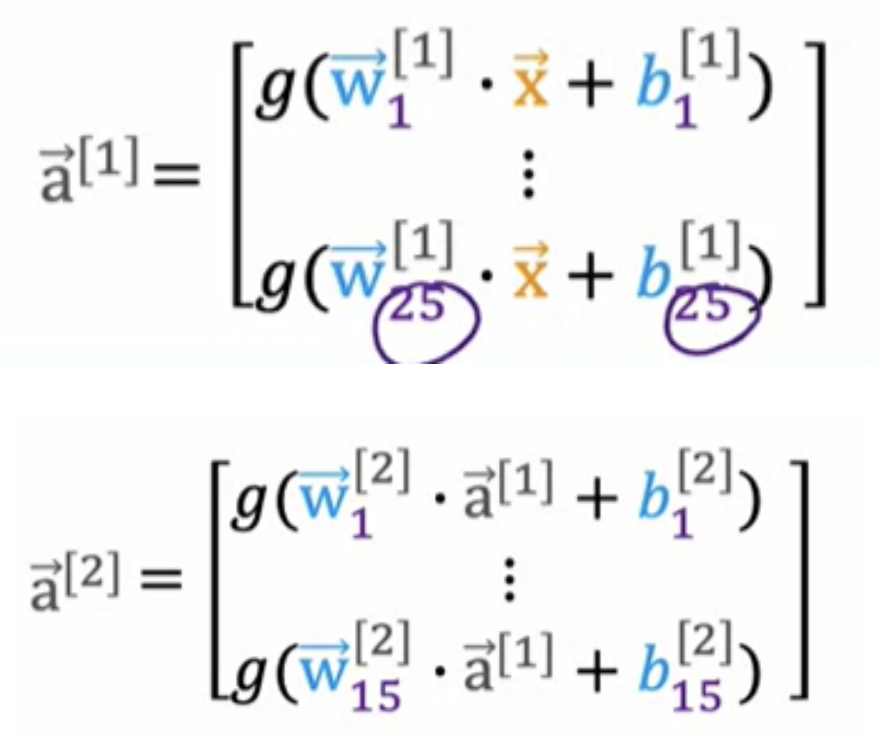
This type of neural network architecture where you have more hidden units initially and then the number of hidden units decreases as you get closer to the output layer. There's also a pretty typical choice when choosing neural network architectures
One of the remarkable things about neural networks is the same algorithm can be applied to so many different applications
TensorFlow is one of the leading frameworks to implementing deep learning algorithms. The other popular tool is PyTorch.
Note that unfortunately there are some inconsistencies between how data is represented in NumPy and in TensorFlow. TensorFlow was designed to handle very large datasets and by representing the data in matrices instead of 1D arrays.
A tensor is a data type that the TensorFlow team had created in order to store and carry out computations on matrices efficiently. So whenever you see tensor just think of that matrix in the picture. Technically a tensor is a little bit more general than the matrix.
There's the TensorFlow way of representing the matrix and the NumPy way of representing matrix. This is an artifact of the history of how NumPy and TensorFlow were created
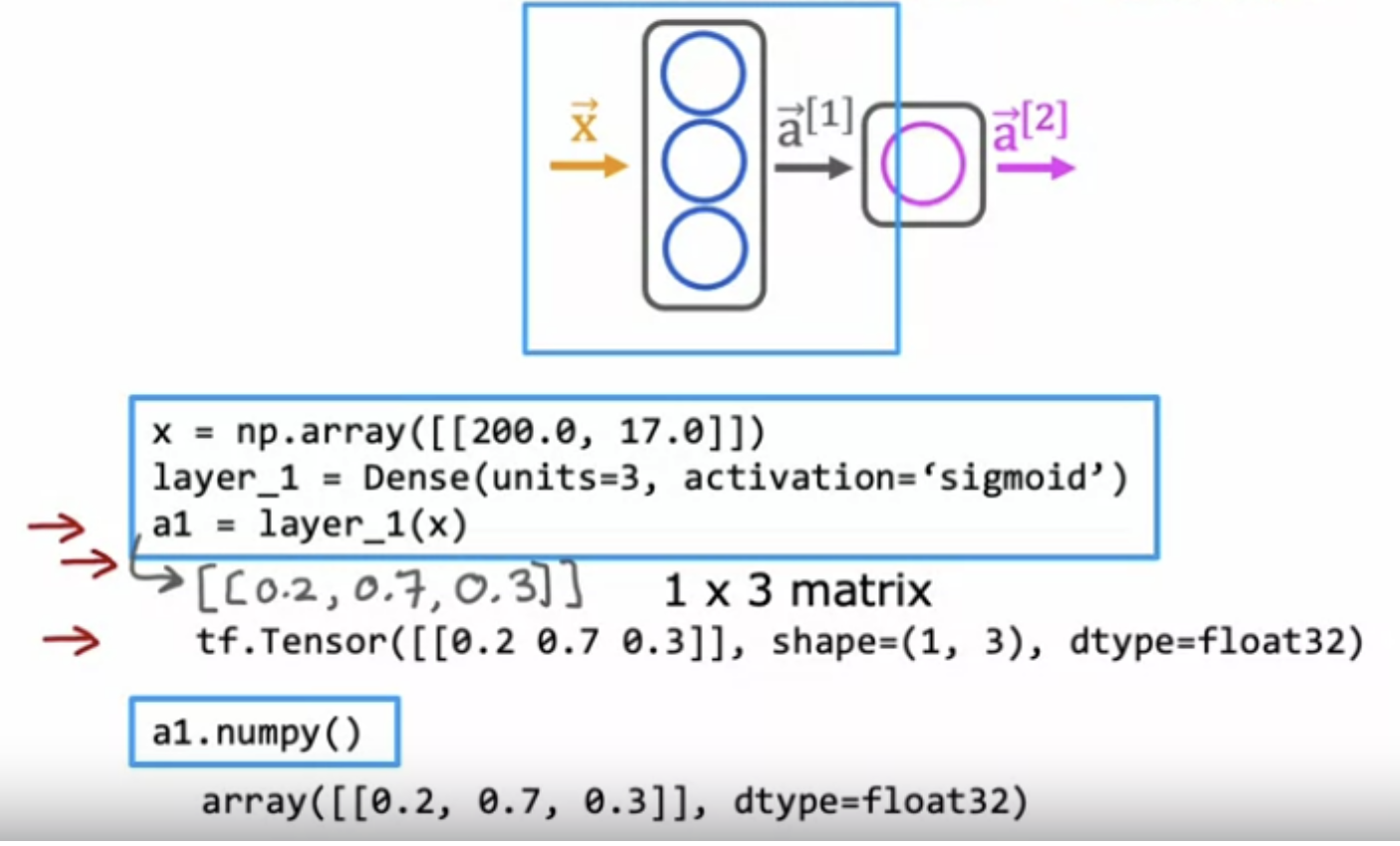
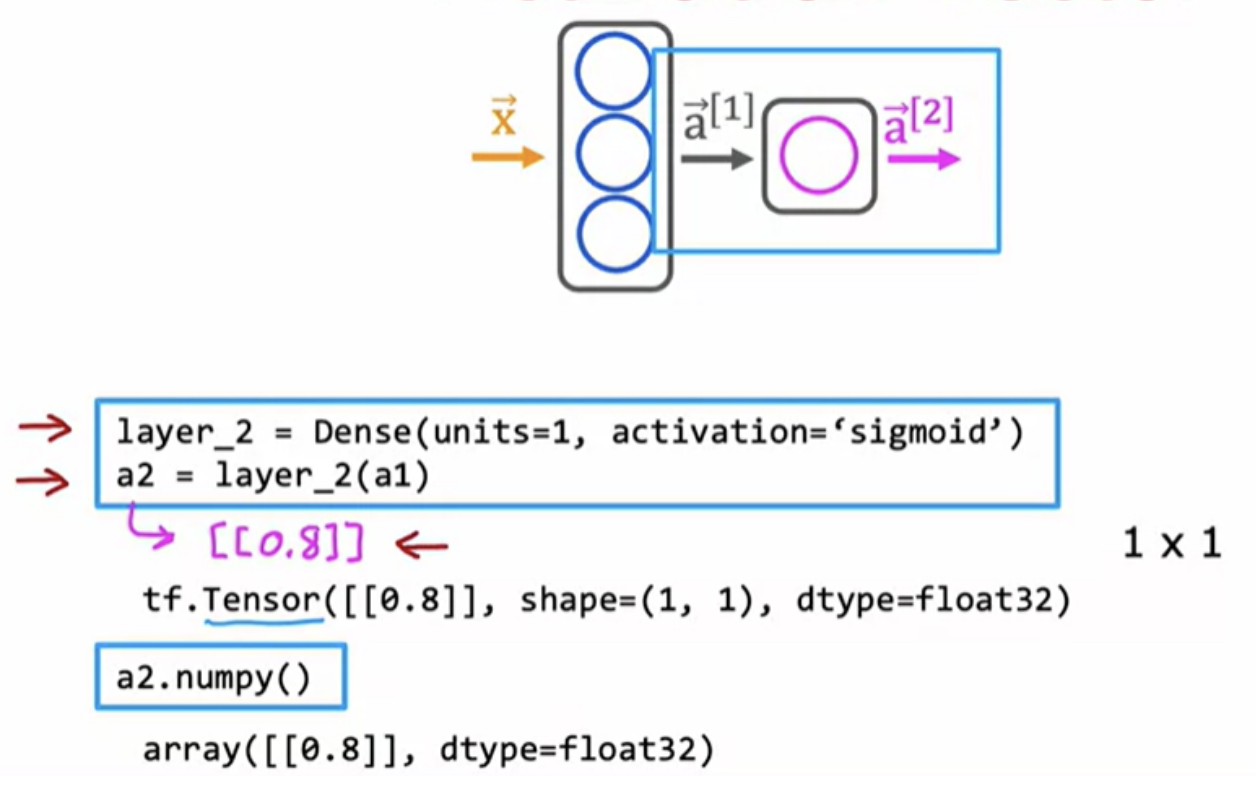
If you want to do forward propogation, you initialize the data X create layer 1 then compute a1 , then create layer 2 and compute a2. So this was an explicit way of carrying out forward propogation one layer of computation at the time.
Tensor flow has a different way of implementing forward propogation as well as learning : First you are going to create layer one and create layer two. But , we can instead (of you manually taking the data and passing it to layer 1 and then taking the activations from layer 1, and pass it to layer 2) tell tensor flow that to take layer 1 and layer 2 and string them together to form a neural network

The sequential function in TensorFlow creates a neural network by sequentially string together these two layers that we just created. Training data for coffee example:
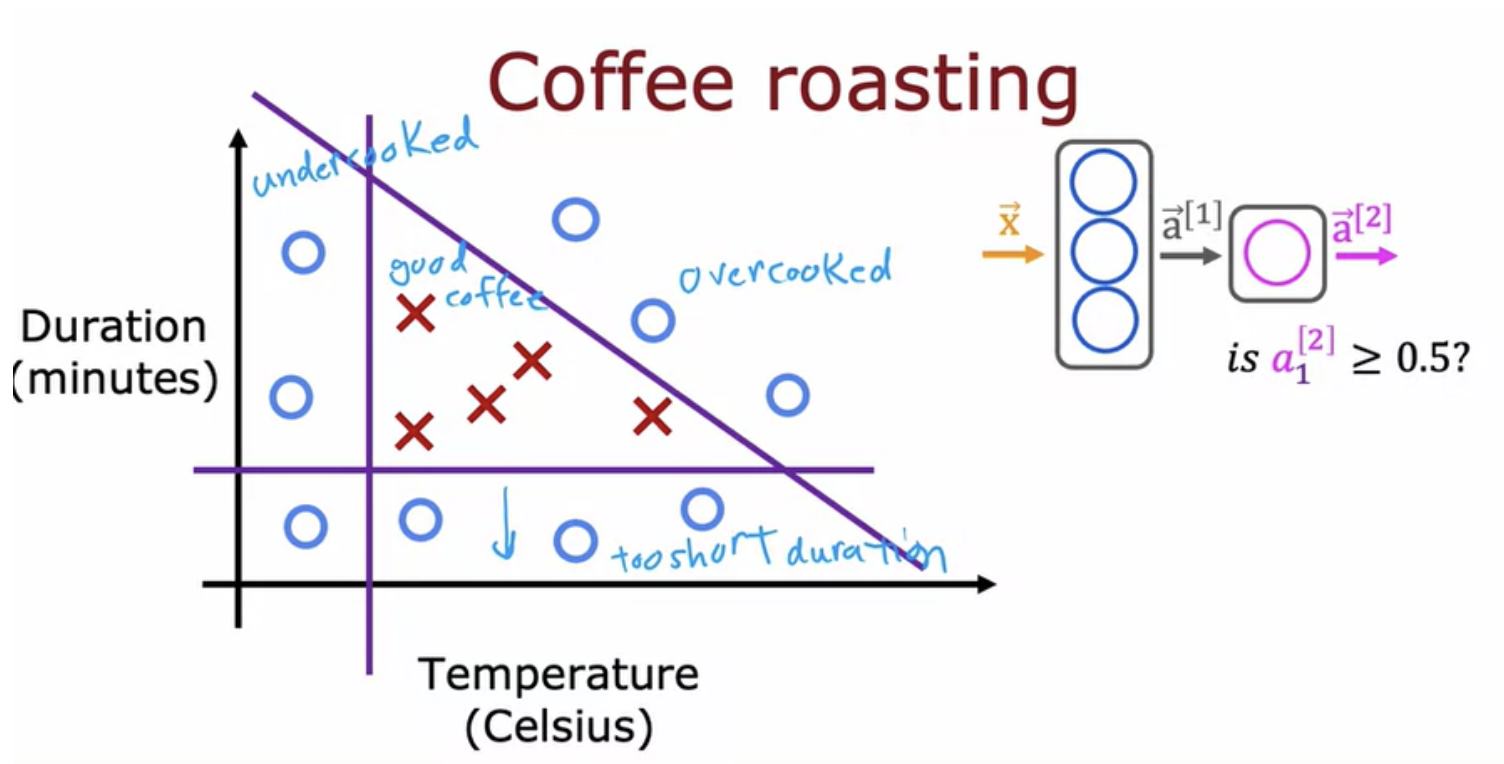

Call model.fit(x,y) tells tensor flow to take this neural network that are created by sequentially string together layers one and two, and to train it on the data (x and y).

In practice most machine learning engineers don't actually implement forward propagation in python that often. They just use libraries like tensorflow and pytorch

Note: Capital case refers to a matrix. Lower case refers to vectors and scalars.
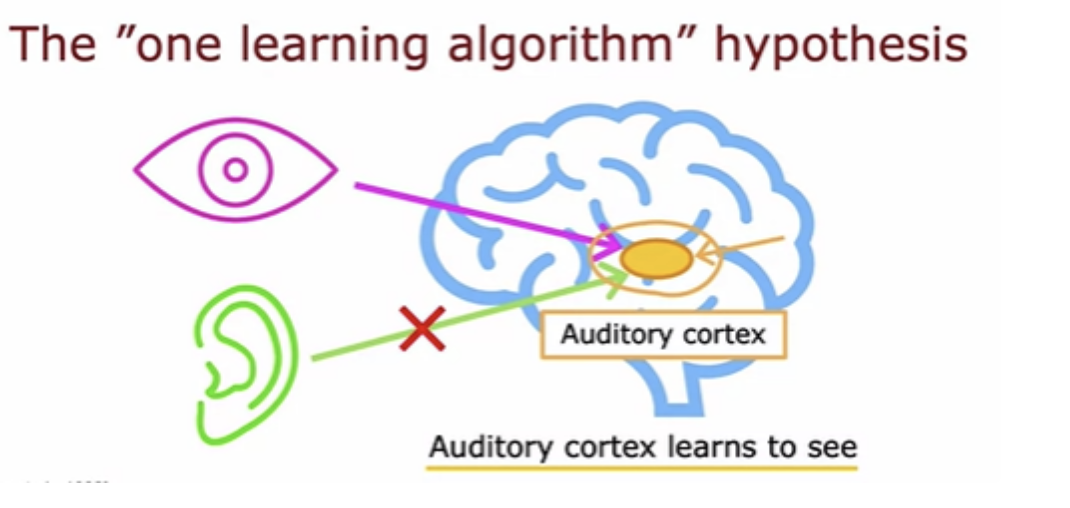
ANI which stands for artificial narrow intelligence. This is an AI system that does one thing, a narrow task, sometimes really well and can be incredibly valuable, such as the smart speaker or self-driving car or web search. AGI is abut anything that human can do. There have been some fascinating experiments on animals that strongly suggests that the same piece of biological brain tissue can do a surprisingly wide range of tasks. This has led to the one learning algorithm hypothesis that maybe a lot of intelligence could be due to one or a small handful of learning algorithms. If only we could figure out what that one or small handful of algorithms are, we may be able to implement that in a computer.someday
One of the reasons that deep learning researchers have been able to scale up neural networks, and thought really large neural networks over the last decade, is because neural networks can be vectorized. They can be implemented very efficiently using matrix multiplications.

We have to decide how many steps to run gradient descent or how long to run gradient descent. Epochs is a technical term for how many steps of a learning algorithm like gradient descent you want to run


If you're using gradient descent to train the parameters of a neural network, then you are repeatedly, for every layer l and for every unit j, update wj . In order to use gradient descent, the key thing you need to compute is partial derivative terms.
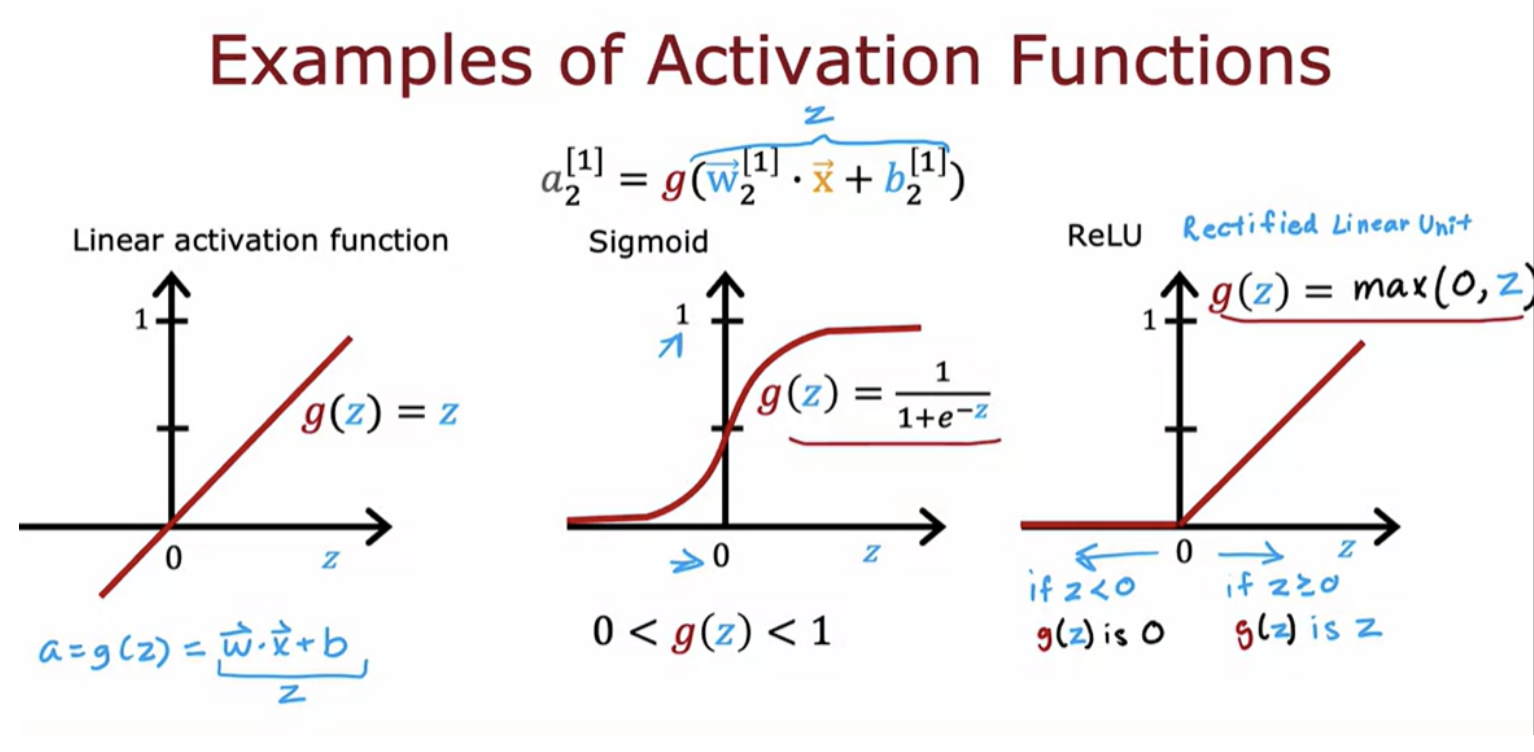
So far, we've been using the sigmoid activation function in all the nodes in the hidden layers and in the output layer. We have started that way because we were building up neural networks by taking logistic regression and creating a lot of logistic regression units and string them together. But if you use other activation functions, your neural network can become much more powerful
ReLU stands for rectified linear unit is an activation function.
Depending on what the target label or the ground truth label y is, there will be one fairly natural choice for the activation function for the output layer. You can choose different activation functions for different neurons in your neural network. If you are working on a classification problem, then the sigmoid activation function will almost always be the most natural choice. Alternatively, if you're solving a regression problem, linear activation function will be a better fit. Example predict how tomorrow's stock price. It can go up or down, so y would be a number that can be either positive or negative. If y can only take on non-negative values, such as if you're predicting the price of a house, ReLU activation function will be better choice since this activation function only takes on non-negative values.
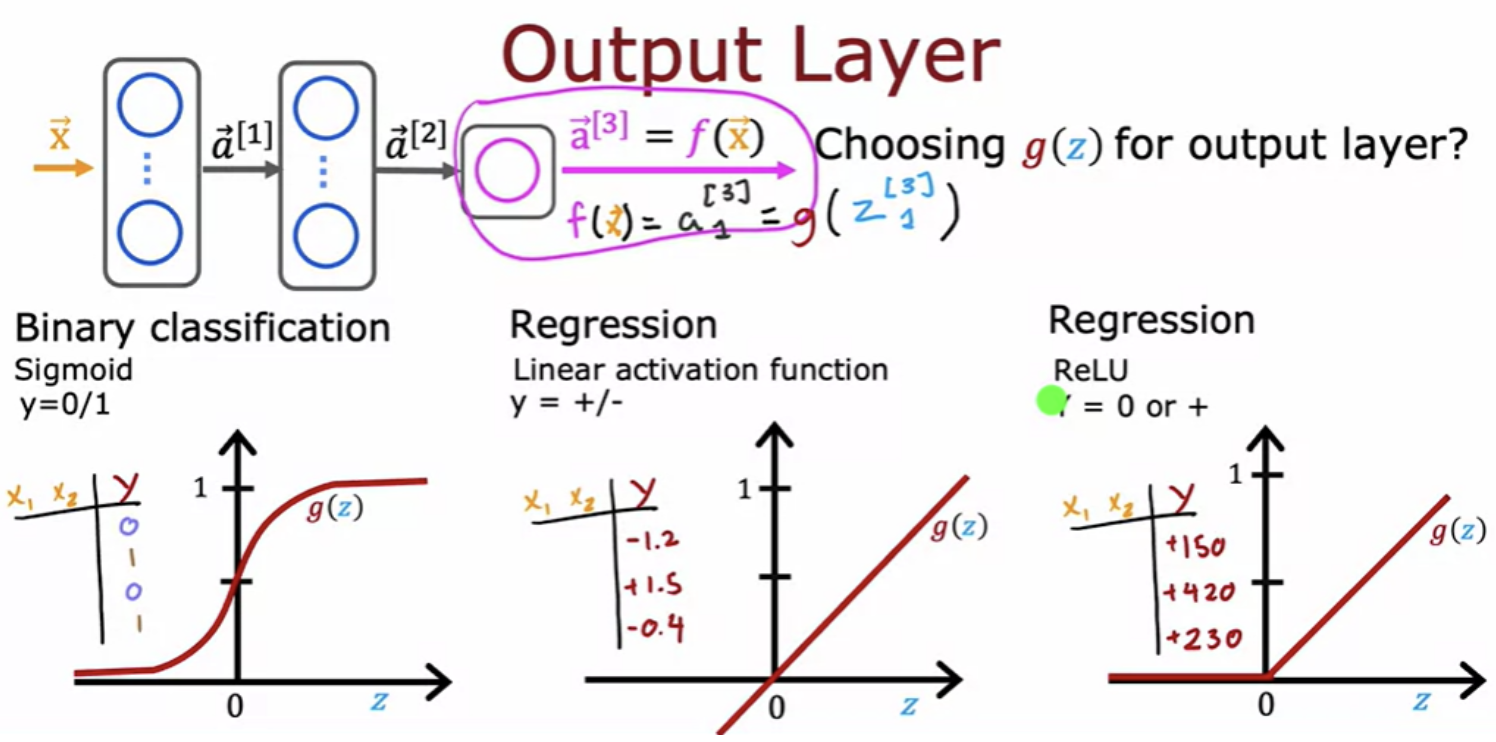
ReLU activation function is by far the most common choice for hidden layers of a neural network. Note that ReLU function goes flat only in one part of the graph, whereas the sigmoid activation function, it goes flat in two places.If you're using gradient descent to train a neural network, then when you have a function that is fat in a lot of places, gradient descents would be really slow.
What would happen if we were to use a linear activation function for all of the nodes in a big neural network?In this case the neural network will become no different than just linear regression. So this would defeat the entire purpose of using a neural network because it would then just not be able to fit anything more complex than the linear regression model
Multiclass classification refers to classification problems where you can have more than just two possible output labels so not just zero or 1. For the handwritten digit classification problems we were just trying to distinguish between digits 0 to 9.
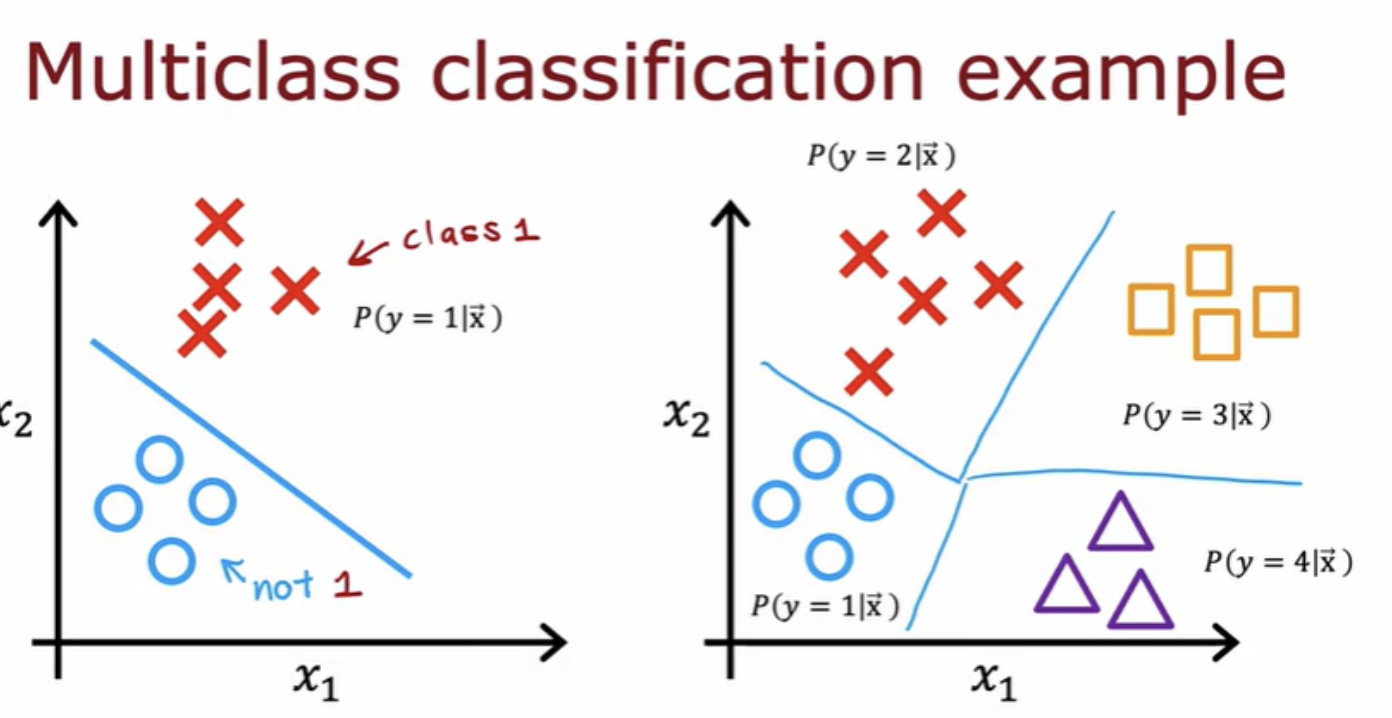
The softmax regression algorithm is a generalization of logistic regression, which is a binary classification algorithm to the multiclass classification contexts. Recall that logistic regression applies when y can take on two possible output values, either zero or one.

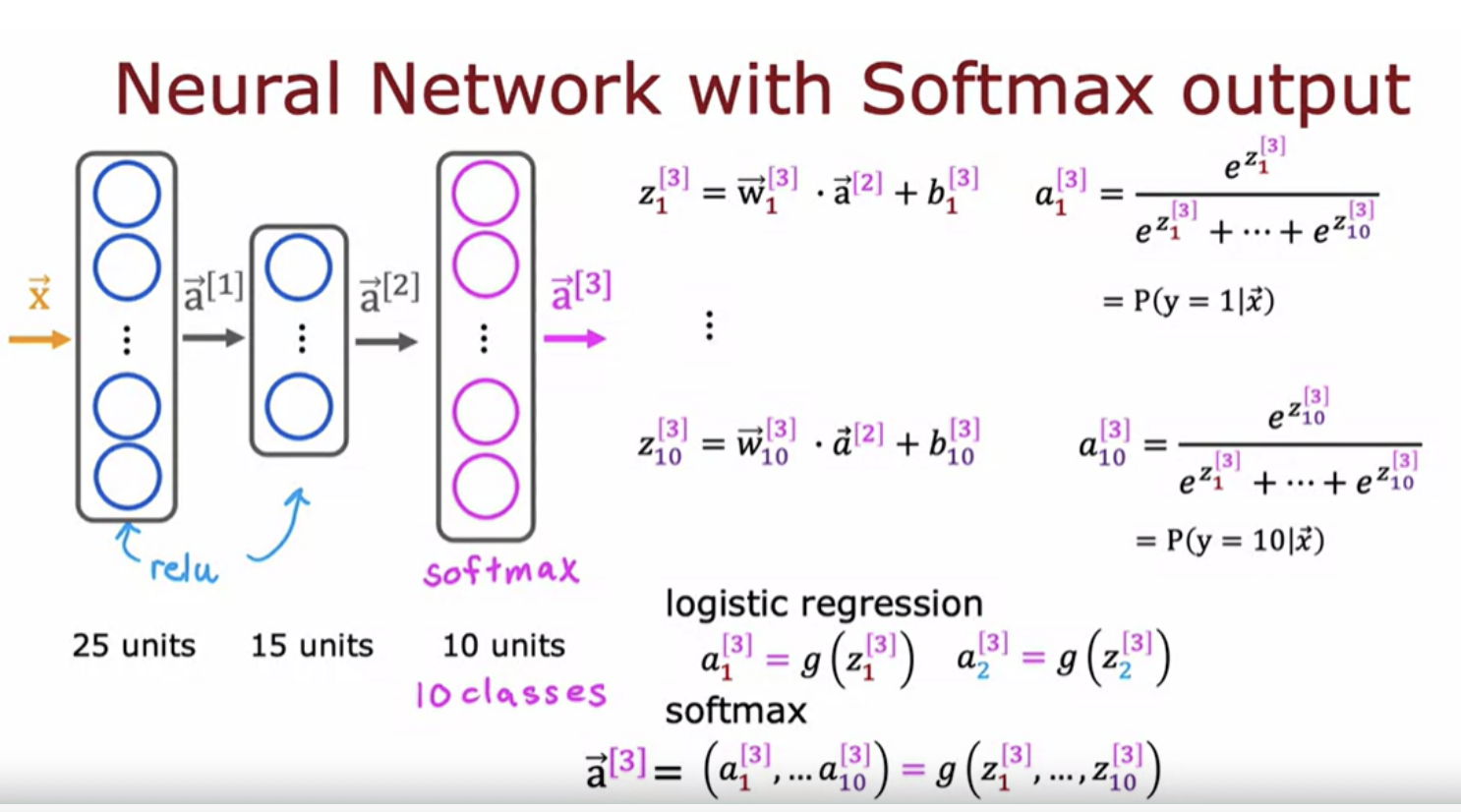
The computer has only a finite amount of memory to store each number () floating-point number in this case). Depending on how you decide to compute the value 2/10,000, the result can have more or less numerical round-off error. We need a different way of formulating softmax that reduces these numerical round-off errors

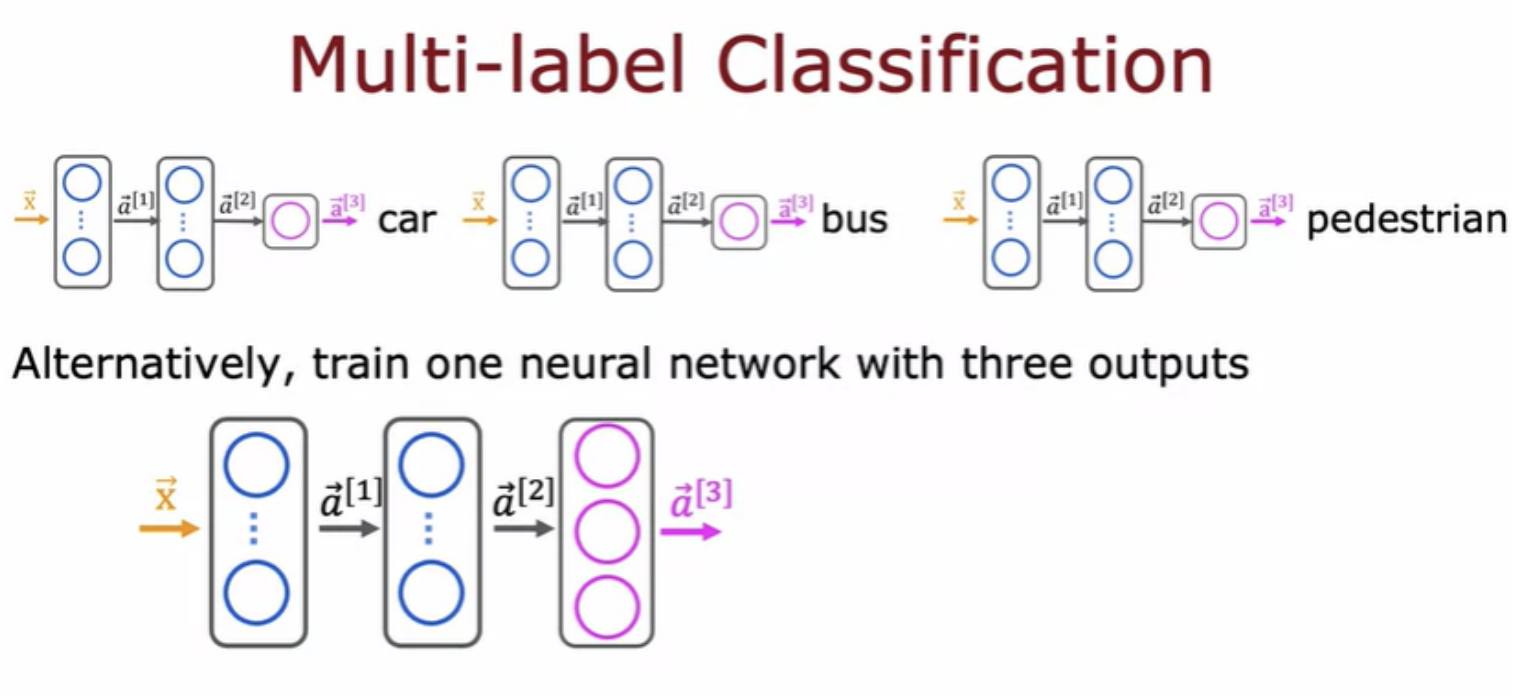
There's a different type of classification problem called a multi-label classification problem, which is where associate of each image, they could be multiple labels. Associated with a single input, image has three different labels. We can build a neural network for multi-label classification

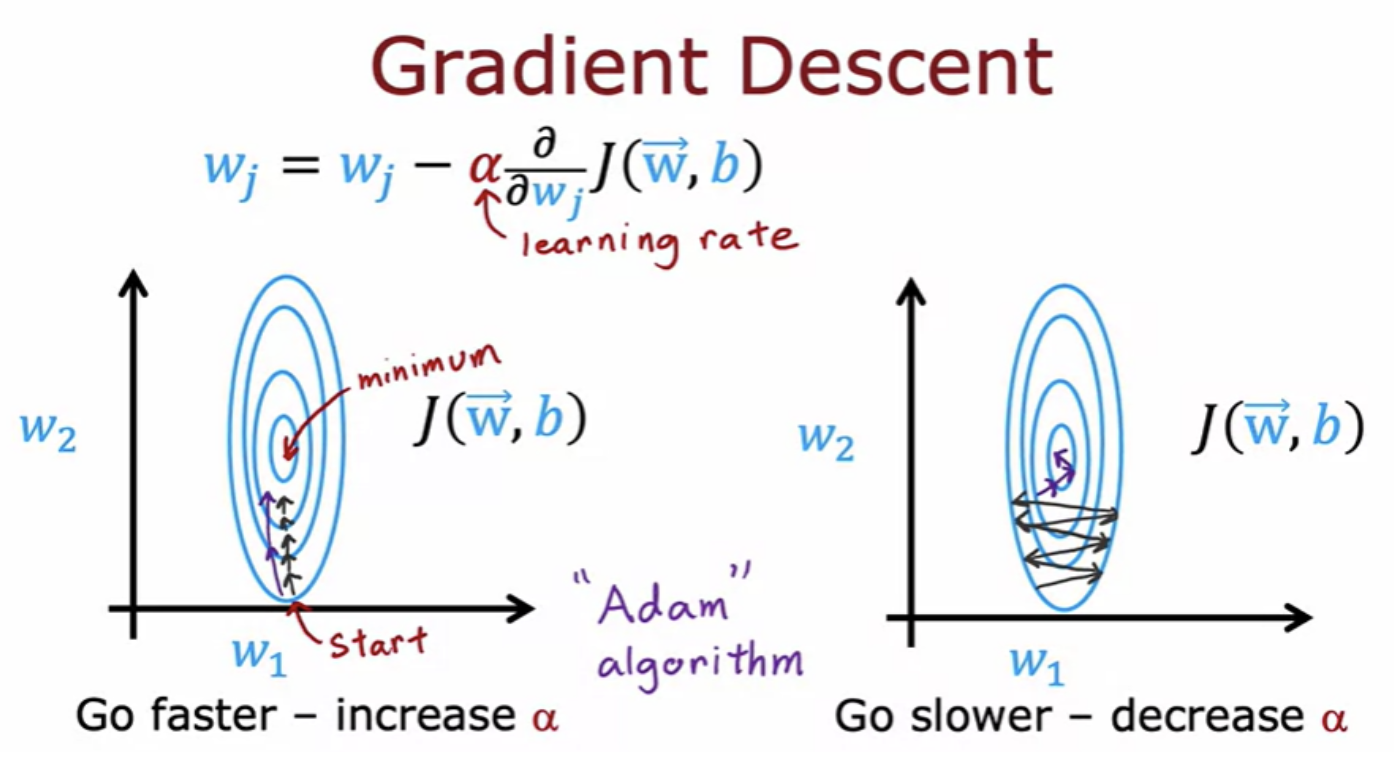
Gradient descent is an optimization algorithm that is widely used in machine learning. There are now some other optimization algorithms for minimizing the cost function, that are even better than gradient descent. Adam algorithm is an example. Depending on how gradient descent is proceeding, sometimes you wish you had a bigger learning rate Alpha, and sometimes you wish you had a smaller learning rate Alpha. The Adam algorithm can adjust the learning rate automatically. Adam stands for Adaptive Moment Estimation
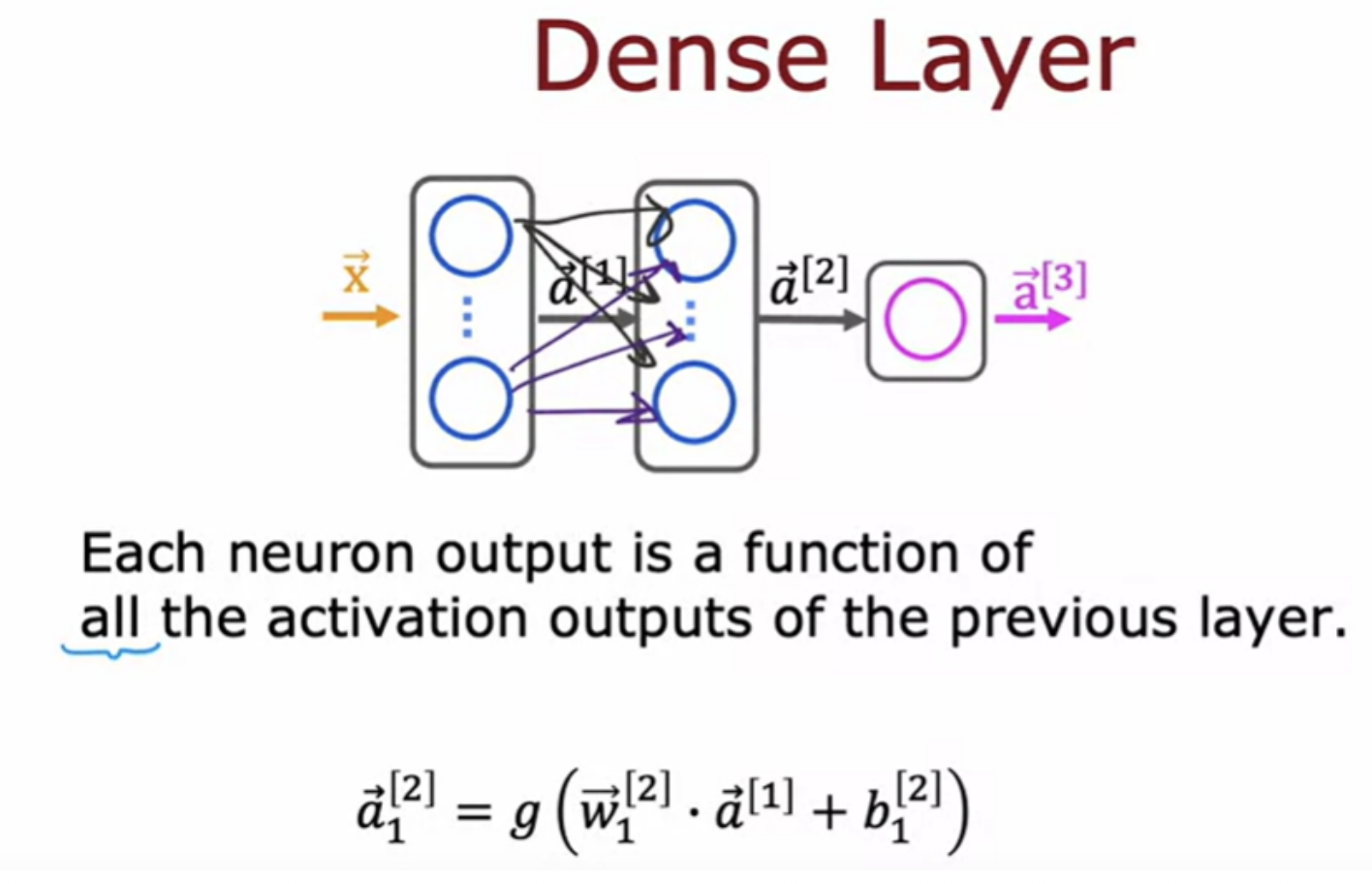
All the neural network layers with you so far have been the dense layer type in which every neuron in the layer gets its inputs all the activations from the previous layer. Just using the dense layer type, you can actually build some pretty powerful learning algorithms. For some applications, someone designing a neural network may choose to use a different type of layer. For example a convolutional layer
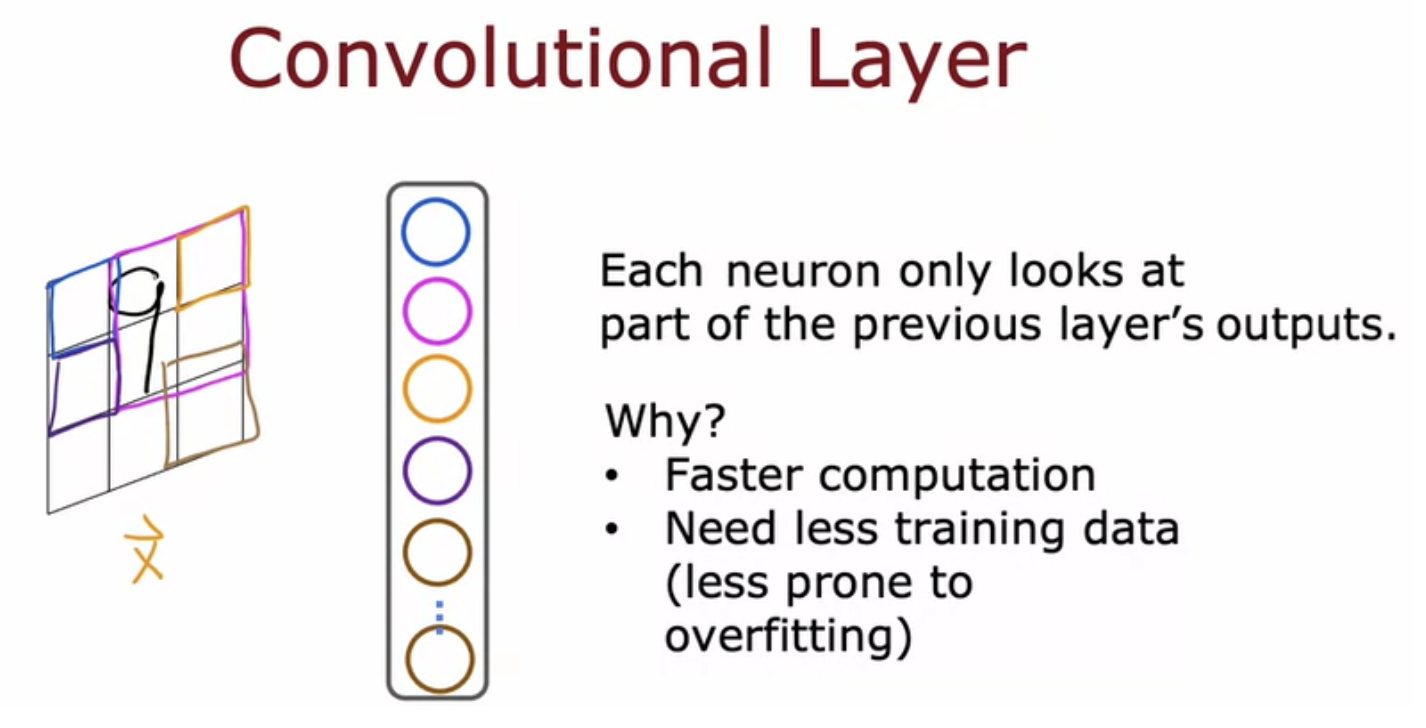
For example, a neuron can only look at the pixels in this little rectangular region. Second nuron also look at the pixels in a limited region of the image. And so on for the third neuron. This it speeds up computation. Secondly, a neural network that uses this type of layer called a convolutional layer can need less training data or alternatively, it can also be less prone to overfitting. This is the type of layer where each neuron only looks at a region of the input image is called a convolutional layer
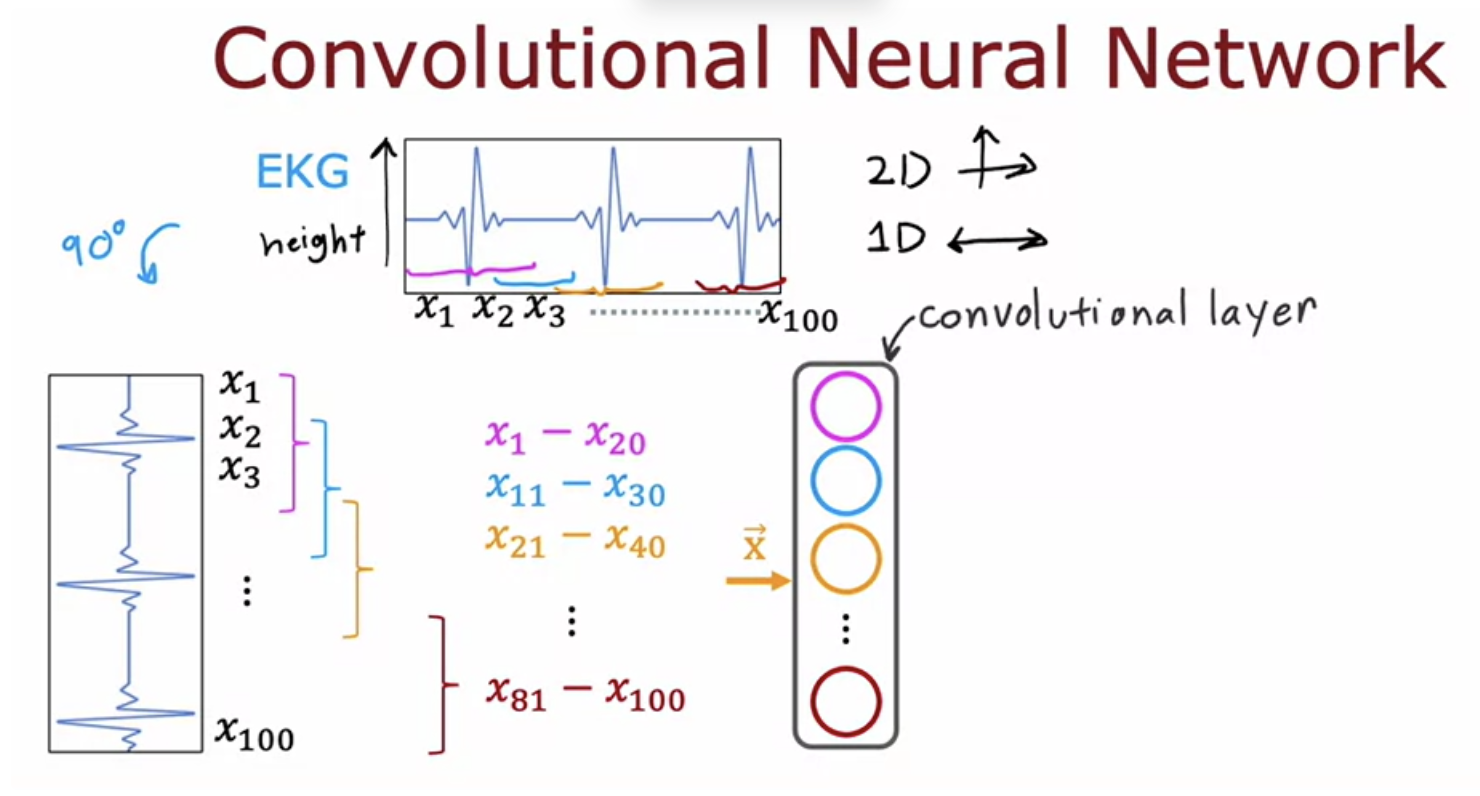
So this is a convolutional layer because these units in this layer looks at only a limited window of the input. The next layer can also be a convolutional layer.
The computation graph is a key idea in deep learning, and it is also how programming frameworks like TensorFlow, automatic compute derivatives of your neural networks

Many years ago, before the rise of frameworks like tensorflow and pytorch, researchers used to have to manually use calculus to compute the derivatives of the neural networks that they wanted to train. And so in modern program frameworks you can specify forwardprop and have it take care of backward propogation for you
